
Machine Learning (ML) trở thành công nghệ cốt lõi thúc đẩy sự phát triển của nhiều ngành công nghiệp. Tuy nhiên, việc đưa các mô hình ML vào ứng dụng thực tế một cách hiệu quả và bền vững lại đặt ra nhiều thách thức. Đây chính là lúc MLOps phát huy vai trò quan trọng của mình nhằm hợp lý hóa toàn bộ vòng đời phát triển và triển khai mô hình ML. Bài viết này sẽ đi sâu giải thích MLOps là gì và phác thảo các bước cần thiết để bạn trau dồi kỹ năng MLOps.
Đọc bài viết để hiểu rõ hơn về:
- MLOps là gì và tại sao cần triển khai MLOps;
- Những nguyên tắc hàng đầu của MLOps;
- Quy trình MLOps workflow điển hình;
- 4 level triển khai MLOps;
- Các kiến thức và kỹ năng cần có của kỹ sư MLOps.
MLOps là gì? Tại sao cần sử dụng MLOps?
MLOps là gì?
MLOps (Machine learning operations) là một tập hợp các phương pháp tự động hóa, đơn giản hóa quy trình phát triển và triển khai học máy (machine learning – ML).
MLOps hợp nhất quá trình phát triển mô hình học máy (Dev) với quá trình triển khai và vận hành hệ thống ML (Ops). MLOps được sử dụng trong suốt vòng đời của một mô hình học máy, từ phát triển mô hình, thử nghiệm, tích hợp, phát hành đến quản lý cơ sở hạ tầng.
Vì sao cần có MLOps?
MLOps đóng vai trò quan trọng việc quản lý toàn diện vòng đời của mô hình học máy, từ việc triển khai mô hình vào môi trường sản xuất đến giám sát hiệu suất.
Nếu không áp dụng MLOps, các tổ chức dễ gặp phải nhiều thách thức như:
- Tăng nguy cơ lỗi trong quá trình triển khai
- Khó mở rộng hệ thống khi quy mô dữ liệu tăng
- Hiệu suất mô hình suy giảm theo thời gian
- Thiếu sự phối hợp giữa các nhóm dữ liệu, kỹ thuật và sản phẩm
MLOps giải quyết những thách thức này bằng cách thiết lập quy trình chuẩn cho việc phát triển, triển khai và giám sát mô hình. Nhờ đó, các mô hình học máy có thể thực hiện hiệu quả các nhiệm vụ, không chỉ đáp ứng nhu cầu ngắn hạn mà còn được đảm bảo tính ổn định, linh hoạt và hiệu quả lâu dài trong thực tế vận hành.
Machine Learning có vai trò gì trong MLOps?
ML là nền tảng kỹ thuật tạo nên các mô hình có độ chính xác cao, có khả năng thực hiện nhiều nhiệm vụ khác nhau như phân loại (classification), dự đoán (prediction) hoặc gợi ý đề xuất (recommendation). Các mô hình ML hoạt động âm thầm trong nền tảng của nhiều ứng dụng khác nhau như chatbot tự động, cải thiện kết quả công cụ tìm kiếm, hệ thống cá nhân hóa nội dung, phát hiện thư rác và gian lận, trợ lý ảo,…
MLOps giúp triển khai thực tế và quản lý liên tục các mô hình đó trong môi trường thực tế. Tóm lại, ML và MLOps là những mảnh ghép bổ sung cho nhau, ML tạo ra mô hình, còn MLOps đảm bảo mô hình đó hoạt động hiệu quả, liên tục và bền vững trong thực tế.
Những nguyên tắc hàng đầu của MLOps
Automation (Tự động hóa)
MLOps tự động hóa các giai đoạn khác nhau trong quy trình học máy để đảm bảo tính lặp lại, tính nhất quán và khả năng mở rộng, từ giai đoạn từ thu thập dữ liệu, tiền xử lý, đào tạo mô hình và xác thực đến triển khai.
Mức độ tự động hóa của các luồng dữ liệu, mô hình ML và code quyết định mức độ hoàn thiện của quy trình ML. Với mức độ hoàn thiện cao hơn, tốc độ đào tạo mô hình mới cũng được cải thiện:
- Quy trình thủ công: Đây là quy trình khoa học dữ liệu điển hình, được thực hiện khi bắt đầu triển khai ML, mang tính thử nghiệm và lặp lại. Mọi bước trong quy trình, chẳng hạn như chuẩn bị và xác thực dữ liệu, huấn luyện và kiểm thử mô hình, đều được thực hiện thủ công bằng các công cụ Rapid Application Development (RAD) như Jupyter Notebooks.
- Tự động hóa quy trình ML: Cấp độ này bao gồm train mô hình tự động (bất cứ khi nào có dữ liệu mới, quy trình model retraining sẽ được kích hoạt) và tự động hóa các bước xác thực dữ liệu và mô hình.
- Tự động hóa quy trình CI/CD: Điểm khác biệt cốt lõi so với cấp độ trước là tự động xây dựng, kiểm tra và triển khai các thành phần Data, ML model và ML training pipeline.
Các yếu tố kích hoạt cho việc đào tạo và triển khai mô hình tự động có thể là các calendar event, messaging, monitoring event cũng như các thay đổi về dữ liệu, model training code và application code.
Continuous Deployment (Triển khai liên tục)
ML asset (tài sản học máy) bao gồm: mô hình, tham số (parameter và hyperparameter), tập lệnh huấn luyện, dữ liệu huấn luyện và kiểm thử. Mỗi asset cần được quản lý về danh tính, phiên bản, sự phụ thuộc và nơi triển khai (như dịch vụ hoặc hạ tầng nền tảng).
MLOps hỗ trợ triển khai liên tục thông qua các hoạt động:
- CI – Continuous Integration (Tích hợp liên tục): Mở rộng kiểm thử từ mã nguồn sang dữ liệu và mô hình.
- CD – Continuous Delivery (Phân phối liên tục): Tự động triển khai pipeline huấn luyện triển khai một dịch vụ dự đoán mô hình ML khác.
- CT – Continuous Training (Huấn luyện liên tục): Tự động đào tạo lại mô hình khi có thay đổi đầu vào.
- CM – Continuous Monitoring (Giám sát liên tục): Theo dõi hiệu suất mô hình và dữ liệu liên tục, gắn liền với các chỉ số kinh doanh.
Đọc chi tiết: Mối quan hệ “mật thiết” giữa CI/CD DevOps
Versioning (Quản lý phiên bản)
Quy trình này bao gồm việc theo dõi các thay đổi trong ML asset để có thể tái tạo kết quả và quay lại phiên bản trước nếu cần. Mỗi thành phần (mã, dữ liệu, mô hình) đều được kiểm duyệt và gắn số phiên bản.
Khả năng tái tạo phải được đảm bảo ở mọi giai đoạn từ xử lý dữ liệu đến triển khai, nghĩa là cùng một đầu vào phải cho ra kết quả giống nhau ở mọi lần thực hiện.
Experiments Tracking (Theo dõi thử nghiệm)
Trái ngược với quy trình phát triển phần mềm truyền thống, trong phát triển ML, nhiều thử nghiệm huấn luyện mô hình có thể được thực hiện song song trước khi đưa ra quyết định mô hình nào sẽ được đưa vào sản xuất.
Một cách để theo dõi nhiều thử nghiệm là sử dụng các Git branch khác nhau, mỗi branch dành riêng cho một thử nghiệm riêng biệt. Output của mỗi branch là một mô hình đã được huấn luyện. Tùy thuộc vào số liệu được chọn, các mô hình học máy đã được huấn luyện sẽ được so sánh với nhau để chọn ra các mô hình phù hợp.
Công cụ hỗ trợ branching với độ ma sát thấp bao gồm: DVC (Data Version Control) – một phần mở rộng của Git và là hệ thống kiểm soát phiên bản mã nguồn mở dành cho các dự án ML; thư viên Weights & Biases (wandb) tự động theo dõi các hyperparameter và metric của các thử nghiệm.
Testing (Kiểm thử)
Kiểm thử trong MLOps giúp đảm bảo độ tin cậy và hiệu suất của các hệ thống học máy. Việc này bắt đầu ngay từ giai đoạn tiền xử lý dữ liệu với các kiểm tra về tính toàn vẹn, định dạng và phân phối.
Trong MLOps, kiểm thử không chỉ dừng lại ở mã nguồn mà mở rộng ra toàn bộ chu trình, bao gồm dữ liệu, mô hình và cơ sở hạ tầng, cụ thể:
- Dữ liệu: Kiểm tra tính toàn vẹn, định dạng và phân phối.
- Mô hình: Kiểm tra độ chính xác, tính công bằng, khả năng khái quát.
- Pipeline: Unit test cho từng thành phần, kiểm thử tích hợp để đảm bảo các phần hoạt động cùng nhau, kiểm thử end-to-end mô phỏng môi trường sản xuất.
Bằng cách thực hiện kiểm thử tự động và liên tục, MLOps giúp phát hiện và khắc phục sự cố nhanh chóng, giảm thiểu rủi ro khi triển khai mô hình vào môi trường thực tế và duy trì hiệu suất ổn định theo thời gian.
Monitoring (Giám sát)
Sau khi mô hình ML được triển khai, cần phải giám sát để đảm bảo mô hình ML hoạt động đúng như mong đợi:
- Theo dõi những thay đổi phụ thuộc trong toàn bộ quá trình xử lý bằng thông báo.
- Theo dõi các bất biến dữ liệu trong quá trình đào tạo và phục vụ đầu vào: Cảnh báo nếu dữ liệu không khớp với lược đồ đã được chỉ định trong bước đào tạo
- Theo dõi xem tính năng đào tạo và phục vụ có tính ra cùng một giá trị không.
- Theo dõi tính ổn định số của mô hình ML.
- Giám sát hiệu suất tính toán của hệ thống ML. Cần thông báo cả hồi quy rò rỉ chậm và hồi quy đột ngột trong hiệu suất tính toán.
- Theo dõi mức độ cũ kỹ của hệ thống trong quá trình sản xuất.
- Theo dõi quá trình tạo tính năng vì chúng ảnh hưởng đến mô hình.
- Theo dõi sự suy giảm chất lượng dự đoán của mô hình ML trên dữ liệu được cung cấp. Cần thông báo cả hồi quy rò rỉ chậm và hồi quy đột ngột về chất lượng dự đoán.
Quy trình MLOps điển hình diễn ra như thế nào?
Quy trình MLOps (MLOps workflow) xoay quanh việc xây dựng các giải pháp liên quan đến học máy ở quy mô sản xuất.
MLOps workflow thường được chia thành hai tầng cơ bản: tầng trên (pipeline) và tầng dưới (driver). Mỗi tầng bao gồm các thành phần như:
- Pipeline: bao gồm các module xây dựng (build), triển khai (deploy), giám sát (monitor).
- Driver: bao gồm dữ liệu (data), mã nguồn (code), artifacts, phần mềm trung gian (middleware) và hạ tầng (infrastructure).
Sơ đồ minh họa dưới đây sẽ giúp bạn hình dung rõ hơn về cách hoạt động của MLOps workflow:
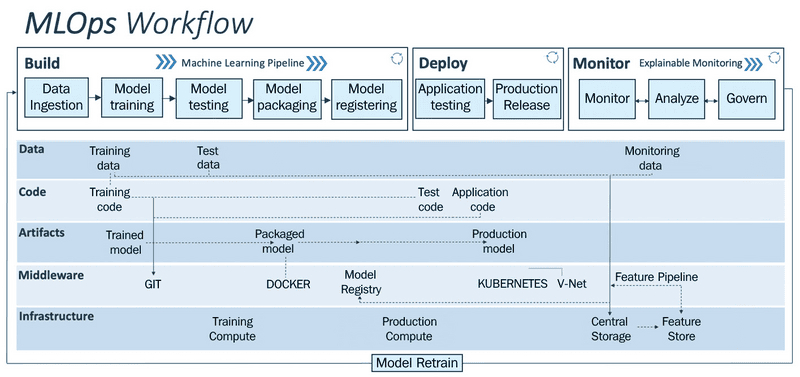
Như đã đề cập, pipeline là tầng trên cùng. Nó được sử dụng để triển khai (deployment) và giám sát (monitoring) các mô hình. Pipeline được kích hoạt bởi các driver nằm phía dưới.
Phần dưới đây sẽ giải thích chi tiết hơn về từng module trong tầng pipeline:
Build (Xây dựng)
Module này được sử dụng để huấn luyện và cung cấp phiên bản cho các mô hình ML. Quy trình trong giai đoạn này bắt đầu với các bước sau:
Data ingestion (Data Ops)
Đây là giai đoạn đầu tiên trong vòng đời MLOps, tập trung vào xử lý dữ liệu đầu vào, bao gồm:
- Xây dựng pipeline tiếp nhận dữ liệu từ nhiều nguồn khác nhau như data lake và data warehouse. Data lake có thể là một trung tâm lưu trữ tất cả các loại dữ liệu có cấu trúc và phi cấu trúc trên quy mô rất lớn.
- Thực hiện các bước xác minh, xác thực dữ liệu bằng các logic xác thực.
- Chạy quy trình ETL (Extract – Transform – Load).
- Sau khi xử lý, dữ liệu được chia thành các tập huấn luyện (training) và kiểm tra (testing).
Model training (Huấn luyện mô hình)
Giai đoạn tiếp theo là huấn luyện mô hình ML để đưa ra dự đoán trong phần sau của dự án. Các mã module sẽ được chạy để thực hiện toàn bộ quá trình model training truyền thống. Bước này bao gồm tiền xử lý dữ liệu, làm sạch dữ liệu và thiết kế thuộc tính. Quá trình này yêu cầu điều chỉnh tham số (hyperparameter tuning), bằng cách thủ công hoặc dùng kỹ thuật tự động như grid search.
Kết quả của bước này là tạo ra một mô hình đã được huấn luyện (trained model).
Kiểm tra mô hình đã được huấn luyện
Mô hình sau khi huấn luyện được đánh giá hiệu suất bằng cách chạy trên tập dữ liệu kiểm tra, đầu ra là các chỉ số đánh giá (metric scores).
Model packaging (Đóng gói mô hình)
Mô hình sẽ được đóng gói bằng Docker để có thể chuyển sang giai đoạn sản xuất. Docker đóng gói toàn bộ ứng dụng thành các thành phần có thể chạy được cùng với mã nguồn, bao gồm hệ điều hành, thư viện và các phụ thuộc cần thiết để chạy mã. Điều này giúp đảm bảo tính đồng nhất và khả năng chạy mô hình trong mọi môi trường triển khai.
Model registration (Lưu trữ mô hình)
Sau khi đóng gói, mô hình sẽ được đăng ký và lưu trữ trong kho mô hình (model registry) để sẵn sàng cho triển khai. Một trained model bao gồm một hoặc nhiều tệp cấu thành để đại diện và chạy model đó. Lúc này, ML pipeline cũng được thực thi.
Deploy (Giai đoạn triển khai)
Module này cho phép vận hành các ML model đã được tạo trong giai đoạn build. Tại đây, việc thực thi và hành vi của mô hình được kiểm tra trong môi trường sản xuất hoặc tương tự sản xuất (test) để đảm bảo tính mạnh mẽ và khả năng thích ứng của mô hình cho việc sử dụng sản xuất.
Testing – Kiểm thử
Kiểm thử là bước quan trọng để xác thực độ bền và hiệu suất của ML model trước khi triển khai sản xuất. Tất cả các trained model đều được kiểm tra trong một môi trường thử nghiệm gần giống môi trường sản xuất để đánh giá kỹ lưỡng về độ tin cậy và khả năng phục hồi.
Trong môi trường thử nghiệm, ML model được triển khai dưới dạng API hoặc dịch vụ phát trực tuyến đến mục tiêu triển khai như Kubernetes cluster, container instance, máy ảo có khả năng mở rộng hoặc thiết bị edge, tùy thuộc vào nhu cầu và trường hợp sử dụng. Sau đó, các dự đoán được đưa ra cho mô hình đã triển khai dựa trên dữ liệu thử nghiệm.
Dự đoán được thực hiện theo lô (batch) hoặc định kỳ, sau đó kiểm tra hiệu suất tổng thể. Nếu đáp ứng các tiêu chuẩn, nó sẽ chuyển sang giai đoạn sản xuất.
Release – Phát hành
Nếu mô hình vượt qua kiểm thử, nó sẽ được chính thức triển khai trong môi trường sản xuất, mang lại giá trị thực tế cho doanh nghiệp.
Monitor (Giai đoạn giám sát)
Các module giám sát (monitor) và triển khai (deploy) luôn đi đôi với nhau. Giai đoạn giám sát sẽ theo dõi và phân tích ứng dụng học máy đã triển khai. Hiệu suất được kiểm tra bằng cách sử dụng các predefined metrics. Mô hình cũng được phân tích bằng cách sử dụng một explainability framework đã xác định trước.
Monitoring – Giám sát
Module này có mục đích là theo dõi tính toàn vẹn dữ liệu, độ lệch mô hình (model drift) và hiệu suất ứng dụng. Sử dụng telemetry data để theo dõi hiệu suất, tình trạng và độ bền của hệ thống sản xuất, ví dụ như dữ liệu từ cảm biến gia tốc, con quay hồi chuyển, độ ẩm, áp suất, nhiệt độ,…
Analyzing – Phân tích
Mục tiêu của việc phân tích là đảm bảo mô hình phù hợp với mục tiêu kinh doanh và các quy định liên quan. Áp dụng các phương pháp giải thích mô hình (model explainability) theo thời gian thực để phân tích đặc tính thiết yếu của mô hình như tính công bằng, độ tin cậy, độ bias, tính minh bạch và lỗi mô hình.
Governing – Quản trị
Bước này thiết lập các cảnh báo và hành động tự động khi mô hình giảm hiệu suất (ví dụ: độ chính xác thấp, độ lệch cao) xuống dưới một ngưỡng xác định trước. Khi đó chuyên gia đảm bảo chất lượng sẽ được thông báo và tự động kích hoạt lại quy trình huấn luyện và triển khai mô hình thay thế.
Ngoài ra, việc tuân thủ luật, các quy định và tiêu chuẩn cũng là một phần quan trọng của giai đoạn quản trị. Áp dụng kiểm toán và báo cáo mô hình để cung cấp khả năng truy xuất nguồn gốc từ đầu đến cuối và khả năng giải thích cho các mô hình trong môi trường sản xuất.
Tóm lại
Quy trình làm việc trong MLOps chủ yếu bao gồm layer trên cùng gọi là pipeline và layer dưới cùng gọi là driver. Các giai đoạn khác nhau liên quan đến việc triển khai một ứng dụng ML hoàn chỉnh bao gồm thu thập dữ liệu (tất cả hành động cần thiết được thực hiện để sửa đổi tập dữ liệu trước khi huấn luyện mô hình), model training (quy trình huấn luyện mô hình ML bằng tập data training), kiểm thử mô hình, trong đó hiệu suất trained model được kiểm tra bằng tập dữ liệu kiểm tra và điểm hiệu suất được trả về.
4 level triển khai MLOps cần biết
MLOps level 0 (Quy trình thủ công)
Level cơ bản nhất, thường áp dụng cho các tổ chức mới bắt đầu sử dụng với ML, phù hợp khi mô hình ít khi được thay đổi hoặc đào tạo. Quy trình được điều hành bởi các data scientist và hoàn toàn thủ công, không có tự động hóa.
Đặc trưng:
- Mọi bước đều được thực hiện thủ công, dựa trên script và tương tác, từ phân tích dữ liệu, chuẩn bị dữ liệu, model training và kiểm định. Quy trình thủ công từ việc thực thi đến chuyển đổi từ bước này sang bước khác.
- Không có hợp tác giữa data scientist – người tạo ra mô hình và các engineer – người phục vụ mô hình. Data scientist bàn giao trained model dưới dạng sản phẩm để nhóm kỹ sư triển khai trên cơ sở hạ tầng API.
- Phát hành mô hình không thường xuyên: Một phiên bản mô hình mới chỉ được triển khai vài lần mỗi năm.
- Không có CI/CD, mọi kiểm thử thường là chạy tay từ notebook hoặc script.
- Nhóm kỹ thuật có thể có thiết lập phức tạp riêng cho cấu hình API, thử nghiệm và triển khai, bao gồm bảo mật, regression và load + canary testing.
Hạn chế:
- Thiếu chủ động giám sát hiệu suất, quy trình không theo dõi hoặc ghi lại các dự đoán và hành động của mô hình.
- Các mô hình dễ bị lỗi khi triển khai trong thế giới thực khi môi trường hoặc dữ liệu thay đổi.
Để giải quyết thách thức này, tốt nhất nên sử dụng các phương pháp MLOps cho CI/CD và continuous training (CT). Bằng cách triển khai ML training pipeline, bạn có thể kích hoạt CT và thiết lập hệ thống CI/CD để nhanh chóng kiểm tra, xây dựng và triển khai ML pipeline.
MLOps level 1 (Tự động hóa ML pipeline)
Mục tiêu của MLOps level 1 là thực hiện huấn luyện liên tục (CT) cho mô hình bằng cách tự động hóa ML pipeline, đảm bảo cung cấp dịch vụ dự đoán mô hình liên tục. Level 1 phù hợp với các giải pháp hoạt động trong môi trường thay đổi liên tục, ví dụ như hành vi khách hàng thay đổi, tỷ lệ giá, điều kiện thị trường biến động,…
Đặc trưng:
- Các bước thử nghiệm học máy được điều phối và thực hiện tự động.
- Nếu ở level 0, bạn triển khai một trained model dưới dạng prediction service vào môi trường sản xuất. Thì đối với level 1, bạn triển khai toàn bộ training pipeline, pipeline này sẽ tự động và định kỳ chạy để phục vụ trained model dưới dạng prediction service.
- Có khả năng tự động huấn luyện lại mô hình khi dữ liệu mới xuất hiện hoặc hiệu suất giảm.
- Pipeline học máy cần có khả năng tái sử dụng, ghép nối và có thể chia sẻ giữa các ML pipeline.
Các thành phần bổ sung:
- Data and Model Validation (Xác thực dữ liệu và mô hình): Pipeline yêu cầu dữ liệu mới, trực tiếp tạo ra một phiên bản trained model trên dữ liệu đó. Do đó, các bước xác thực dữ liệu tự động và xác thực mô hình là cần thiết ở level này.
- Feature Store: Kho lưu trữ tập trung, nơi chuẩn hóa định nghĩa, lưu trữ và truy cập các thuộc tính để huấn luyện và phục vụ mô hình.
- Metadata Management: Thông tin về mỗi lần thực thi ML pipeline được ghi lại để hỗ trợ data and artifacts lineage, khả năng tái tạo và so sánh. Nó cũng giúp bạn gỡ các lỗi và bất thường.
- ML Pipeline Trigger (điểm kích hoạt): Bạn có thể thiết lập trigger để tự động hóa các ML production pipeline huấn luyện lại mô hình với dữ liệu mới, tùy thuộc vào trường hợp sử dụng của bạn:
- Theo yêu cầu (On-demand)
- Theo lịch trình (On a schedule)
- Khi có dữ liệu huấn luyện mới (On availability of new training data)
- Khi hiệu suất mô hình suy giảm (On model performance degradation)
- Khi có những thay đổi đáng kể trong phân phối dữ liệu (evolving data profiles).
Hạn chế:
- Khó thử nghiệm nhanh các ý tưởng ML mới.
- Nếu quản lý nhiều ML pipelinetrong môi trường sản xuất, cần thiết lập CI/CD để tự động hóa việc xây dựng, kiểm tra và triển khai các ML pipeline.
MLOps level 2 (Tự động hóa CI/CD pipeline)
Level 2 tập trung nâng cao tốc độ triển khai, độ tin cậy và khả năng mở rộng. Level này phù hợp với môi trường phải cập nhật mô hình nhanh chóng, như sản phẩm quy mô lớn hoặc thời gian thực.
Với hệ thống này, các data scientist nhanh chóng khám phá những ý tưởng mới xoay quanh kỹ thuật đặc trưng, kiến trúc mô hình và hyperparameters.
Đặc trưng:
- CI/CD pipeline mạnh mẽ tự động hóa toàn bộ vòng đời: từ phát triển, test đến triển khai.
- Hỗ trợ triển khai và huấn luyện lại mô hình hàng ngày, thậm chí hàng giờ, cập nhật chúng trong vài phút và triển khai lại trên hàng nghìn máy chủ cùng lúc.
- Phân phối mô hình dưới dạng service trên quy mô lớn.
Các bước:
- Phát triển và thử nghiệm: Bạn lặp đi lặp lại thử nghiệm các thuật toán ML và mô hình mới, nơi các bước thử nghiệm được điều phối. Output là mã nguồn của các bước ML pipeline step, sau đó được đẩy vào kho lưu trữ mã nguồn.
- Tích hợp pipeline liên tục: Bạn xây dựng mã nguồn và chạy nhiều bài kiểm tra khác nhau. Output là các thành phần pipeline (packages, executables, artifacts) để được triển khai ở giai đoạn sau.
- Phân phối pipeline liên tục: Bạn triển khai các artifact được tạo ra bởi giai đoạn CI vào môi trường mục tiêu. Output là một pipeline đã được triển khai với việc triển khai mô hình mới.
- Trigger tự động: Pipeline được tự động thực thi trong môi trường sản xuất dựa trên lịch trình hoặc phản ứng với một trigger. Output là một trained model được đẩy vào model registry.
- Phân phối mô hình liên tục: Bạn phục vụ trained model dưới dạng prediction service cho các dự đoán. Output là một prediction service mô hình đã được triển khai.
- Giám sát: Bạn thu thập số liệu thống kê về hiệu suất mô hình dựa trên dữ liệu trực tiếp. Output là một trigger để thực thi pipeline hoặc để thực hiện một chu trình thử nghiệm mới.
Các thành phần chính:
- Kiểm soát mã nguồn (Source control)
- Dịch vụ kiểm thử và xây dựng (Test and build services)
- Dịch vụ triển khai (Deployment services)
- Kho đăng ký mô hình (Model registry)
- Kho thuộc tính (Feature store)
- Kho siêu dữ liệu ML (ML metadata store)
- Bộ điều phối ML pipeline (ML pipeline orchestrator).
MLOps level 3 (MLOps nâng cao)
Đây là cấp độ cao nhất, tích hợp các tính năng như giám sát liên tục, đào tạo lại mô hình, tự phục hồi và quản trị toàn diện. Hệ thống tự động theo dõi tình trạng hao mòn, tự sửa chữa và thậm chí cập nhật phần mềm được tối ưu hóa hoàn toàn, giống như một môi trường MLOps hoàn chỉnh. Phù hợp cho các tổ chức lớn, hệ thống phức tạp và yêu cầu khắt khe về kiểm soát, bảo mật và audit.
Đặc trưng:
- Tự động hóa toàn diện: Toàn bộ luồng công việc ML (từ dữ liệu đến triển khai) được tự động hóa hoàn toàn.
- CI/CD/CT tích hợp sâu: Tự động tích hợp, triển khai và huấn luyện liên tục, cập nhật mô hình nhanh chóng.
- Quản lý mô hình tập trung: Hệ thống quản lý phiên bản mô hình toàn diện, đảm bảo khả năng tái tạo.
- Giám sát và cảnh báo thông minh: Tự động giám sát hiệu suất mô hình, phát hiện độ lệch dữ liệu và đưa ra cảnh báo.
Các nhóm kiến thức và kỹ năng cần có của kỹ sư MLOps
Kỹ năng lập trình cơ bản và tư duy thuật toán
Đây là kỹ năng cốt lõi trong việc phát triển mô hình học máy hiệu quả. Bạn cần thành thạo:
- Cấu trúc dữ liệu và thuật toán
- Kiến thức toán học nền tảng như thống kê, đại số tuyến tính giúp củng cố nhiều kỹ thuật ML, cho phép các chuyên gia phân tích dữ liệu và diễn giải kết quả mô hình một cách chính xác.
- Ngôn ngữ lập trình phổ biến như Python, Go, Bash
- Thư viện và framework để triển khai các thuật toán học máy và xây dựng mô hình: TensorFlow, PyTorch, scikit-learn
- Các khái niệm về quy trình như: data preprocessing (tiền xử lý dữ liệu), feature engineering (trích xuất đặc trưng), model evaluation (đánh giá mô hình), và hyperparameter tuning (tinh chỉnh siêu tham số)
Tài liệu tham khảo về Python:
- Python là gì: Tổng quan định nghĩa, Cú pháp và Thư viện Python
- Code Python cơ bản: Hướng dẫn chi tiết các lệnh Python cơ bản
- Các lệnh trong Python giúp phân biệt Fresher và Senior Developer
- Học Python online dễ dàng với 15+ nguồn tài liệu và thực hành
Tài liệu tham khảo về Go:
- Học Golang đầy đủ chỉ với 9 bước
- 10+ khái niệm và cú pháp Golang cơ bản
- Golang Backend: Các bước phát triển backend với Golang cơ bản
Hệ thống kiểm soát phiên bản
Cho phép theo dõi, so sánh và quản lý thay đổi mã qua thời gian, hỗ trợ làm việc nhóm hiệu quả và tái tạo thí nghiệm. Kỹ năng liên quan:
- Sử dụng Git cơ bản và nâng cao
- Branching, merge, conflict resolution
- Kết nối với CI/CD pipeline và quản lý lịch sử mô hình
Tài liệu tham khảo:
- Git là gì: Định nghĩa, Thuật ngữ cơ bản và Cách cài đặt
- Git vs GitHub: Các điểm khác nhau và Cách kết hợp
- Tổng hợp 20+ các lệnh Git cơ bản cần biết
- Top 10+ kỹ thuật Git nâng cao
- Lộ trình học Git chi tiết từ Cơ bản đến Nâng cao
Hiểu biết về điện toán đám mây
Điện toán đám mây (Cloud Computing) là việc cung cấp các dịch vụ điện toán qua internet thay vì sử dụng máy chủ cục bộ hoặc thiết bị cá nhân. Điện toán đám mây cho phép đổi mới nhanh hơn, tài nguyên linh hoạt và quy mô kinh tế. Bạn cần nắm vững cách thức vận hành và triển khai mô hình ML trên hạ tầng cloud. Bắt đầu từ việc tìm hiểu các kiến thức về điện toán đám mây như:
- Dịch vụ: Compute, storage, database, networking, AI/ML
- Mô hình: public, private, hybrid
- Các hình thức: IaaS, PaaS, SaaS
- Các nhà cung cấp: AWS, Azure, GCP
Tài liệu tham khảo:
- Điện toán đám mây là gì? Khái niệm, phân loại và ứng dụng
- Ưu điểm của điện toán đám mây với doanh nghiệp và IT Developer
- Dịch vụ điện toán đám mây: So sánh các nhà cung cấp hàng đầu
- 20+ tài liệu điện toán đám mây hữu ích nhất cho chuyên gia IT
Kỹ năng Container hóa
Container là một cấu trúc trong đó cgroups, namespaces và chroot được sử dụng để đóng gói và cô lập hoàn toàn một tiến trình. Tiến trình được đóng gói này gọi là image, chia sẻ kernel của máy chủ với các container khác, khiến container nhỏ hơn và nhanh hơn đáng kể so với máy ảo. Container giúp đóng gói và triển khai các mô hình ML một cách linh hoạt, ổn định và nhất quán. Một số nhóm kiến thức về ảo hóa cần nắm:
- Kiến thức về Docker: Image, container, volume, network
- Hiểu cơ chế hoạt động của cgroups, namespaces, chroot
- Tối ưu hóa container để phục vụ mô hình nhanh và hiệu quả
Tài liệu tham khảo:
- Docker là gì? Hãy để Senior DevOps Engineer trả lời cho bạn!
- Docker Container là gì? Cách sử dụng Docker Container hiệu quả
- Articles about Containers – The New Stack
- What are Containers?
- Explore top posts about Containers
Kiến thức cơ bản về học máy
MLOps không thể tách rời khỏi Machine Learning, vì toàn bộ quá trình vận hành phụ thuộc vào việc hiểu và quản lý mô hình học máy. Do đó, người làm MLOps cần có nền tảng vững chắc về ML, không nhất thiết để trực tiếp xây dựng mô hình, nhưng đủ để hiểu cách mô hình vận hành, đánh giá hiệu suất, phát hiện lỗi, và phối hợp hiệu quả với nhóm Data Scientist.
Một số kỹ năng Machine Learning quan trọng trong MLOps gồm: các khái niệm và kỹ thuật chính cho phép hệ thống học từ dữ liệu và đưa ra dự đoán hoặc quyết định mà, các thuật toán có thể xác định mẫu trong dữ liệu và cải thiện theo thời gian, quy trình tiền xử lý dữ liệu, lựa chọn đặc trưng, huấn luyện mô hình, số liệu đánh giá,…
Tài liệu tham khảo:
Kiến thức cơ bản về kỹ thuật dữ liệu
Không có dữ liệu tốt thì không thể có mô hình tốt. Với vai trò là người “đưa mô hình vào sản xuất”, người làm MLOps cần nắm vững các kỹ năng kỹ thuật dữ liệu (Data Engineering) để xây dựng và quản lý pipeline dữ liệu ổn định, bảo trì dễ dàng và đủ linh hoạt để mở rộng, cho phép data scientist chuyển đổi dữ liệu thành những thông tin hữu ích. Việc thu thập, lưu trữ, xử lý, chuyển đổi và phục vụ dữ liệu cần phải được tự động hóa và giám sát liên tục.
Các kỹ năng quan trọng gồm:
- Thiết kế và tối ưu pipeline xử lý dữ liệu (ETL/ELT)
- Tích hợp dữ liệu từ nhiều nguồn (API, DB, files…)
- Xử lý dữ liệu lớn với công cụ như Hadoop, Spark, Kafka
- Sử dụng ngôn ngữ như SQL và Python để thao tác dữ liệu hiệu quả
Tài liệu tham khảo:
Các nguyên tắc MLOps
Người làm MLOps không chỉ cần biết làm thế nào để triển khai một mô hình, mà quan trọng hơn là phải biết làm thế nào để triển khai đúng cách, có thể lặp lại và kiểm soát được. Các nguyên tắc MLOps giúp định hình một quy trình khoa học, đáng tin cậy và có thể mở rộng trong thực tế.
Những nguyên tắc này bao gồm:
- Hợp tác: Thúc đẩy sự hợp tác giữa các data scientist, developers và nhóm vận hành để đảm bảo sự thống nhất về mục tiêu mô hình, hiệu suất và quản lý vòng đời.
- Tự động hóa: Tự động hóa quy trình làm việc để đào tạo mô hình, thử nghiệm, triển khai và giám sát nhằm nâng cao hiệu quả, giảm lỗi và tăng tốc vòng đời phát triển.
- Version Control: Triển khai kiểm soát phiên bản cho cả mã và dữ liệu để theo dõi thay đổi, tái tạo các thử nghiệm và duy trì nguồn gốc mô hình.
- Tích hợp và triển khai liên tục (CI/CD) : Thiết lập quy trình CI/CD phù hợp với học máy để tạo điều kiện lặp lại và triển khai mô hình nhanh chóng.
- Giám sát và quản lý: Liên tục giám sát hiệu suất mô hình và drift data trong quá trình sản xuất để đảm bảo các mô hình vẫn hiệu quả và tuân thủ yêu cầu.
- Khả năng mở rộng: Thiết kế các hệ thống có khả năng mở rộng để xử lý khối lượng công việc khác nhau và thích ứng với những thay đổi về khối lượng và độ phức tạp của dữ liệu.
- Khả năng tái tạo: Đảm bảo các thí nghiệm có thể tái tạo một cách đáng tin cậy bằng cách chuẩn hóa môi trường và quy trình làm việc, giúp việc xác thực và lặp lại trên các mô hình dễ dàng hơn.
Nắm vững các nguyên tắc này là điều kiện tiên quyết để một hệ thống ML vận hành trơn tru, minh bạch và sẵn sàng mở rộng.
Tài liệu và khóa học tham khảo:
Thành phần MLOps
Hiểu được từng thành phần giúp người làm MLOps xác định được điểm mạnh, điểm yếu và nhu cầu cải tiến trong hệ thống của mình.
Ba nhóm thành phần chính:
- Development (Phát triển): Bao gồm mọi thứ liên quan đến việc tạo ML model, chẳng hạn như data extraction, data analysis, feature engineering, và ML model training.
- Operations (Vận hành): Bao gồm các thành phần liên quan đến việc triển khai, giám sát và duy trì các ML model trong môi trường sản xuất. Điều này có thể bao gồm quản lý phát hành, cung cấp mô hình và giám sát hiệu suất.
- Governance (Quản trị): Bao gồm các chính sách và quy định liên quan đến ML model. Điều này bao gồm kiểm tra và theo dõi mô hình, khả năng giải thích mô hình và các quy định về bảo mật & tuân thủ.
Tài liệu và khóa học tham khảo:
Infrastructure as Code
Infrastructure as Code (IaC) là phương pháp tiếp cận hiện đại để quản lý và cung cấp cơ sở hạ tầng IT thông qua các tệp cấu hình machine-readable, thay vì các quy trình thủ công. Với người làm MLOps, Infrastructure as Code (IaC) cho phép quản lý toàn bộ tài nguyên hạ tầng như server, storage, networking… bằng mã, có thể kiểm thử, tái sử dụng và triển khai đồng nhất qua nhiều môi trường.
Các công cụ IaC như Terraform và AWS CloudFormation là những công cụ quen thuộc trong bộ kỹ năng của người làm MLOps chuyên nghiệp.
Tài liệu và khóa học tham khảo:
- Visit Dedicated Terraform Roadmap
- What is Infrastructure as Code?
- Terraform Course for Beginners
- 8 Terraform Best Practices
- DataCamp – MLOps Fundamentals
Các câu hỏi thường gặp về MLOps
MLOps có gì khác DevOps?
MLOps và DevOps đều chia sẻ mục tiêu là tự động hóa, hợp tác và tăng hiệu quả trong quá trình phát triển, triển khai phần mềm. Tuy nhiên, hai lĩnh vực này có những điểm khác biệt rõ rệt do bản chất công việc:
- DevOps hướng đến việc thu hẹp khoảng cách giữa nhóm phát triển và nhóm vận hành. DevOps giúp đảm bảo các thay đổi mã được tự động kiểm tra, tích hợp và triển khai vào môi trường sản xuất một cách hiệu quả và đáng tin cậy. DevOps thúc đẩy văn hóa hợp tác để đạt được chu kỳ phát hành nhanh hơn, cải thiện chất lượng ứng dụng và sử dụng tài nguyên hiệu quả hơn.
- Trong khi đó, MLOps kế thừa tinh thần DevOps, áp dụng các nguyên tắc DevOps, nhưng được thiết kế riêng cho các dự án học máy. MLOps tập trung vào việc tự động hóa vòng đời ML, giúp đảm bảo các mô hình không chỉ được phát triển mà còn được triển khai, giám sát và đào tạo lại một cách có hệ thống và liên tục. Việc triển khai và tích hợp phần mềm truyền thống có thể đơn giản, nhưng MLOps đặt ra những thách thức riêng về việc thu thập dữ liệu, đào tạo mô hình, xác thực, triển khai, giám sát và đào tạo lại liên tục.
Đọc chi tiết: DevOps roadmap: Lộ trình 16 bước học chi tiết trở thành DevOps
Kỹ sư MLOps có cần phải biết lập trình không?
Có. Một kỹ sư MLOps không chỉ triển khai mô hình ML, mà còn cần tích hợp mô hình vào pipeline xử lý dữ liệu, viết script tự động hóa việc huấn luyện, kiểm thử, giám sát mô hình,) xử lý lỗi hệ thống khi mô hình không hoạt động đúng,…
Do đó, bạn phải biết lập trình (thường là Python, Bash, đôi khi là Go hoặc Java), sử dụng các công cụ như Docker, Kubernetes, Airflow, Terraform…
Việc đào tạo các mô hình ngôn ngữ lớn (LLMOps) có khác với MLOps truyền thống không?
Cùng điểm qua một số tiêu chí so sánh LLMOps và MLOps truyền thống:
- Tài nguyên tính toán: Việc đào tạo và tinh chỉnh các mô hình large language thường liên quan đến việc thực hiện nhiều phép tính hơn gấp bội trên các tập dữ liệu lớn. Để tăng tốc quá trình này, phần cứng chuyên dụng như GPU được sử dụng cho các hoạt động song song dữ liệu nhanh hơn nhiều. Tiếp cận các tài nguyên tính toán chuyên dụng này trở nên thiết yếu cho cả quá trình đào tạo và triển khai mô hình large language.
- Transfer Learning: Không giống như phần lớn mô hình ML truyền thống được tạo hoặc đào tạo từ đầu, nhiều mô hình large language bắt đầu từ một mô hình nền tảng và được fine-tune với dữ liệu mới để cải thiện hiệu suất trong một lĩnh vực cụ thể hơn. Fine-tuning cho phép đạt hiệu suất tối ưu cho các ứng dụng cụ thể, sử dụng ít dữ liệu và ít tài nguyên tính toán hơn.
- Phản hồi từ người dùng: Một cải tiến lớn trong việc huấn luyện LLM là thông qua học tăng cường từ phản hồi của con người (RLHF). Vì các tác vụ của LLM thường mở, phản hồi từ người dùng cuối là yếu tố then chốt để đánh giá và cải thiện hiệu suất. Việc tích hợp vòng lặp phản hồi này vào các LLMOps pipeline có thể nâng cao đáng kể hiệu suất của LLM.
- Hyperparameter Tuning: Trong ML truyền thống, Hyperparameter Tuning chủ yếu nhằm cải thiện độ chính xác, nhưng với LLM, nó còn giúp giảm chi phí và yêu cầu tính toán trong quá trình huấn luyện và suy luận. Điều chỉnh các thông số như batch sizes hay learning rates có thể ảnh hưởng lớn đến chi phí và tốc độ huấn luyện. Do đó, việc theo dõi và tối ưu hóa quá trình tuning là cần thiết cho cả ML truyền thống và LLM, dù với mục tiêu khác nhau.
- Chỉ số hiệu suất: Các mô hình ML truyền thống có chỉ số hiệu suất rõ ràng như độ chính xác hay điểm F1, dễ dàng tính toán. Tuy nhiên, khi đánh giá LLM, chúng ta sử dụng một bộ các chỉ số tiêu chuẩn khác như BLEU hay ROGUE, đòi hỏi cân nhắc và kỹ thuật đặc biệt khi triển khai.
AI đang ảnh hưởng đến MLOps như thế nào?
Gen AI có thể cải thiện quy trình làm việc của MLOps bằng cách tự động hóa các tác vụ đòi hỏi nhiều công sức như dọn dẹp và chuẩn bị dữ liệu, từ đó nâng cao hiệu quả và cho phép data scientist và engineer tập trung vào các hoạt động chiến lược hơn.
Ngoài ra, gen AI còn có thể tự động tạo và đánh giá các mô hình học máy để phát triển nhanh hơn. Tuy nhiên, sự phổ biến của Gen AI cũng đặt ra thách thức về độ tin cậy, tính minh bạch khó kiểm soát khi AI “ngẫu hứng” sinh ra pipeline hoặc kiến trúc mô hình không rõ lý do, hay việc dùng dữ liệu huấn luyện không đại diện có thể làm AI duy trì định kiến và kết quả sai lệch.
Tổng kết
Để thành thạo MLOps, bạn cần xây dựng nền tảng vững chắc về ML và kỹ thuật phần mềm, đồng thời làm quen với các công cụ và quy trình tự động hóa. Nắm vững MLOps sẽ giúp bạn triển khai các hệ thống ML một cách hiệu quả, đáng tin cậy và có khả năng mở rộng, đáp ứng nhu cầu ngày càng cao của các ứng dụng AI hiện đại. Đây là một lĩnh vực đầy triển vọng, nhưng cũng đòi hỏi sự nghiêm túc và học tập liên tục để theo kịp sự phát triển của công nghệ.
