
Trong thời đại số, Big Data (dữ liệu lớn) không chỉ là khái niệm công nghệ mà còn là “vũ khí chiến lược” của doanh nghiệp hiện đại. Bài viết này sẽ giúp bạn tiếp cận Big Data một cách đầy đủ và dễ hiểu nhất, từ giải thích bản chất Big Data là gì đến hướng dẫn cách ứng dụng thực tế.
Đọc bài viết này để biết:
- Big Data là gì? Lịch sử hình thành và phát triển của Big Data
- Sự khác nhau giữa Data và Big Data
- 7 đặc điểm và tính chất quan trọng của Big Data
- Ứng dụng và công nghệ của Big Data
- Tương lai của Big Data
Big Data là gì?
Big Data (dữ liệu lớn) là tập hợp dữ liệu có khối lượng khổng lồ, tốc độ tạo mới cực nhanh và mang đa dạng định dạng, vượt xa khả năng xử lý của hệ quản trị cơ sở dữ liệu (RDBMS) truyền thống. Dữ liệu này có thể đến từ log truy cập web, clickstream quảng cáo, giao dịch khách hàng, mạng xã hội, cho đến tín hiệu cảm biến IoT.
Khi dữ liệu vượt quá sức chứa và khả năng phân tích của hệ thống cũ, doanh nghiệp cần ứng dụng các công nghệ lưu trữ – xử lý phân tán (như Hadoop, Spark) để khai thác giá trị. Đây cũng là lý do xuất hiện các vị trí chuyên trách như Big Data Engineer, người thiết kế hạ tầng dữ liệu lớn đảm bảo dữ liệu luôn chảy thông suốt, chính xác và tối ưu chi phí.
Lịch sử hình thành và phát triển của Big Data
Những năm 1960 – Những năm 1970
Khái niệm Big Data chưa tồn tại, nhưng data center đầu tiên và relational database (CSDL quan hệ) đã đặt nền móng cho lưu trữ và xử lý dữ liệu.
Những năm 1980 – Những năm 1990
Dữ liệu chủ yếu được lưu trữ và xử lý trên RDBMS (Oracle, IBM DB2, Microsoft SQL Server). Doanh nghiệp bắt đầu xây dựng data warehouse (kho dữ liệu) để lưu trữ dữ liệu từ nhiều hệ thống phục vụ BI (business intelligence), nhưng dung lượng vẫn ở mức GB hoặc TB, chưa đủ lớn để gọi là Big Data.
Những năm 2000 (trước 2005)
Sự phát triển của Internet và thương mại điện tử làm tăng đáng kể khối lượng dữ liệu, nhưng các công nghệ truyền thống vẫn đáp ứng được nhu cầu phân tích ở thời điểm này.
Từ năm 2005 – 2010
- Khái niệm Big Data xuất hiện: Khi lượng dữ liệu do người dùng Internet tạo ra bùng nổ – đặc biệt từ Facebook, YouTube, và các nền tảng chia sẻ, phát trực tuyến – dữ liệu không chỉ lớn về dung lượng mà còn đa dạng định dạng (văn bản, hình ảnh và video) và tốc độ tạo ra cực nhanh.
- Khái niệm “Big Data” được dùng để phân biệt với dữ liệu thông thường, nhấn mạnh 3 đặc trưng chính: Volume (khối lượng), Velocity (tốc độ), Variety (đa dạng).
- Hadoop (2005) – framework mã nguồn mở ra đời, giúp lưu trữ và xử lý dữ liệu lớn phân tán hiệu quả. Cùng thời điểm, NoSQL trở nên phổ biến nhờ khả năng lưu trữ dữ liệu phi cấu trúc và bán cấu trúc linh hoạt.
Những năm 2010 đến nay
- Apache Spark xuất hiện, thay thế Hadoop MapReduce trong nhiều bài toán nhờ tốc độ xử lý nhanh gấp hàng chục lần.
- IoT (Internet of Things) mở ra kỷ nguyên mới, khi thiết bị cảm biến và vật dụng thông minh liên tục tạo dữ liệu real-time.
- Machine learning và AI vừa tạo thêm dữ liệu vừa đòi hỏi cơ sở hạ tầng phân tích mạnh mẽ hơn.
- Cloud computing trở thành giải pháp lưu trữ, xử lý Big Data tối ưu với khả năng mở rộng (scalable) linh hoạt.
- Graph databases được ứng dụng mạnh mẽ để phân tích quan hệ dữ liệu phức tạp, mạng xã hội cho đến hệ thống gợi ý (recommendation system).
Sự khác nhau giữa Data và Big Data
Nhiều người vẫn nghĩ Big Data chỉ khác Data thông thường ở kích thước, nhưng thực tế sự khác biệt giữa chúng còn nằm ở cách lưu trữ, xử lý, giá trị khai thác và công nghệ hỗ trợ.
Bảng dưới đây sẽ giúp bạn hiểu rõ hơn về sự khác nhau giữa Data và Big Data:
| Đặc điểm | Data (Dữ liệu truyền thống) | Big Data |
| Khái niệm | Tập hợp các thông tin hoặc dữ liệu ở dạng số, văn bản, hình ảnh, âm thanh, video; có thể xử lý dễ dàng bằng công cụ truyền thống. | Tập hợp dữ liệu khổng lồ, phức tạp với khối lượng, tốc độ, đa dạng cao đến mức công cụ truyền thống không thể xử lý hiệu quả. |
| Khối lượng | Vừa phải, từ vài MB đến GB; dễ quản lý và lưu trữ trên RDBMS hoặc server đơn. | Rất lớn, thường từ terabyte (TB), petabyte (PB) đến exabyte (EB), yêu cầu kiến trúc lưu trữ phân tán. |
| Tốc độ | Tạo mới hoặc cập nhật chậm, xử lý theo từng đợt (batch) định kỳ. | Tạo mới, cập nhật liên tục với tốc độ cực nhanh; cần xử lý gần thời gian thực (near real-time) hoặc thời gian thực (real-time). |
| Định dạng | Chủ yếu dữ liệu có cấu trúc; một phần nhỏ là bán cấu trúc. | Đa dạng: có cấu trúc (structured), bán cấu trúc (semi-structured), không có cấu trúc (unstructured) như bao gồm văn bản, hình ảnh, video, dữ liệu cảm biến, tập tin nhật ký, và dữ liệu luồng. |
| Tính phức tạp | Thấp; dễ quản lý nhờ có cấu trúc dữ liệu rõ ràng và mô hình dữ liệu quan hệ. | Cao; dữ liệu không đồng nhất, không đầy đủ hoặc không nhất quán, đòi hỏi quá trình làm sạch dữ liệu và kỹ thuật dữ liệu phức tạp. |
| Giá trị | Phục vụ báo cáo hoạt động, thống kê cơ bản, hỗ trợ quyết định ngắn hạn. | Tạo ra các hiểu biết chiến lược, dự báo xu hướng, huấn luyện AI/ML để ra quyết định tự động và tối ưu hóa quy trình. |
| Công cụ xử lý | Excel, SQL databases (MySQL, PostgreSQL), phần mềm BI đơn giản. | Apache Hadoop, Apache Spark, NoSQL databases (MongoDB, Cassandra), Apache Kafka |
| Công nghệ lưu trữ | Hệ quản trị cơ sở dữ liệu quan hệ (RDBMS), máy chủ vật lý hoặc điện toán đám mây cơ bản. | Hệ thống lưu trữ phân tán như HDFS (Hadoop Distributed File System), Amazon S3, Google Cloud Storage, Azure Data Lake. |
| Ứng dụng | Quản lý dữ liệu nghiệp vụ (CRM, ERP), báo cáo tài chính, phân tích KPI. | Phân tích hành vi khách hàng, dự đoán thị trường, AI & Machine Learning, IoT analytics, fraud detection real-time. |
7 đặc điểm và tính chất quan trọng của Big Data
Big Data không chỉ đơn giản là “dữ liệu có khối lượng lớn” mà còn bao gồm nhiều đặc điểm và tính chất quan trọng giúp hiểu rõ hơn về cách quản lý, phân tích và khai thác dữ liệu. Để hiểu và khai thác Big Data hiệu quả, bạn cần nắm rõ 7 đặc điểm (7Vs) của Big Data:
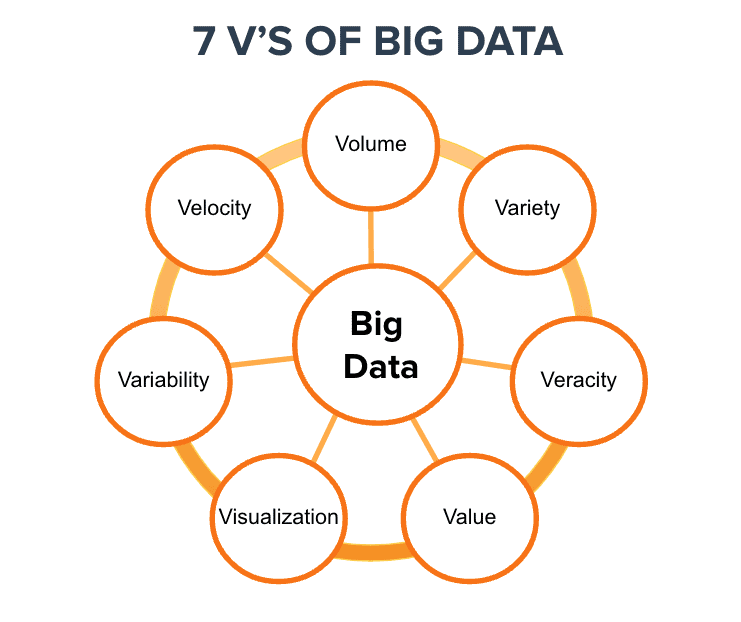
Volume (Khối lượng)
Yếu tố rõ rệt nhất của Big Data chính là khối lượng dữ liệu khổng lồ, tính bằng terabyte (TB), petabyte (PB) cho đến exabyte (EB) và vẫn không ngừng tăng lên mỗi ngày. Nguồn dữ liệu có thể đến từ giao dịch thương mại điện tử, thiết bị IoT, log hệ thống, camera an ninh, cảm biến công nghiệp, mạng xã hội hay các ứng dụng di động.
Khối lượng khổng lồ này vượt quá khả năng lưu trữ, quản lý và xử lý của các hệ thống truyền thống, đòi hỏi doanh nghiệp phải áp dụng các công nghệ và kiến trúc Big Data chuyên dụng như Hadoop, Spark, Distributed File System để đảm bảo lưu trữ hiệu quả, truy xuất nhanh và phân tích kịp thời.
Velocity (Tốc độ)
Một đặc trưng quan trọng của Big Data là tốc độ tạo ra và xử lý dữ liệu cực nhanh. Mỗi ngày, hàng tỷ gigabyte dữ liệu mới được tạo ra từ các giao dịch thương mại điện tử, mạng xã hội, thiết bị IoT, cảm biến, log hệ thống và ứng dụng di động.
Nhiều trường hợp yêu cầu xử lý dữ liệu ngay lập tức (real-time) hoặc gần thời gian thực (near real-time) để kịp thời đưa ra quyết định. Ví dụ: hệ thống phát hiện gian lận giao dịch ngân hàng, giám sát thiết bị công nghiệp, điều hướng xe tự lái, hoặc phân tích xu hướng dư luận trên mạng xã hội.
Velocity đặt ra yêu cầu cao về hạ tầng tính toán, kiến trúc hệ thống streaming và năng lực xử lý song song để đảm bảo dữ liệu được thu thập, phân tích và phản hồi kịp thời.
Variety (Đa dạng)
Dữ liệu lớn không chỉ đến từ nhiều nguồn khác nhau mà còn tồn tại ở nhiều định dạng đa dạng:
- Structured data (dữ liệu có cấu trúc) thường được lưu trữ trong các hệ quản trị cơ sở dữ liệu quan hệ với bảng và cột rõ ràng.
- Semi-structured data (dữ liệu bán cấu trúc) như JSON hoặc XML chứa các tag, key-value nhưng không tuân theo một schema cứng nhắc.
- Unstructured data (dữ liệu phi cấu trúc) bao gồm văn bản, email, tài liệu Word, PDF, hình ảnh, video, audio, file log ứng dụng, dữ liệu từ mạng xã hội hay cảm biến IoT.
Veracity (Độ tin cậy)
Một trong những thách thức lớn nhất của Big Data là đảm bảo độ tin cậy (veracity) của dữ liệu. Dữ liệu lớn thường không đồng nhất, có thể thiếu, không đầy đủ, chứa nhiễu hoặc sai lệch do lỗi nhập liệu, cảm biến hỏng, dữ liệu bị trùng lặp, hay thông tin không được cập nhật. Nếu không xử lý cẩn thận, các vấn đề này sẽ dẫn đến kết quả phân tích sai lệch, ảnh hưởng đến quyết định kinh doanh.
Do đó, các tổ chức cần xây dựng quy trình data cleaning (làm sạch dữ liệu) và validation (xác thực dữ liệu) nghiêm ngặt để đảm bảo dữ liệu đủ chất lượng, từ đó tạo ra insight chính xác và đáng tin cậy.
Value (Giá trị)
Mục tiêu cuối cùng của Big Data không chỉ dừng lại ở việc thu thập hay lưu trữ dữ liệu khổng lồ, mà quan trọng hơn là khai thác giá trị tiềm ẩn bên trong dữ liệu đó.
Thông qua các phương pháp phân tích dữ liệu nâng cao như machine learning, data mining và AI, doanh nghiệp có thể chuyển đổi dữ liệu thô thành insight hữu ích, hỗ trợ ra quyết định chiến lược nhanh chóng và chính xác hơn, tối ưu quy trình vận hành, giảm chi phí, tăng doanh thu, hoặc thậm chí tạo ra các sản phẩm, dịch vụ mới mang tính đột phá. Nói cách khác, giá trị của Big Data nằm ở khả năng biến dữ liệu thành lợi thế cạnh tranh thực sự.
Visualization (Trực quan hóa)
Với khối lượng và độ phức tạp lớn, trực quan hóa dữ liệu trở thành yếu tố quan trọng giúp con người dễ dàng hiểu và khai thác insight từ Big Data.
Các biểu đồ, dashboard BI hay báo cáo tương tác không chỉ trình bày dữ liệu một cách trực quan mà còn hỗ trợ người dùng phát hiện nhanh các xu hướng, bất thường và mối liên hệ ẩn giấu mà phân tích số liệu thô khó thể hiện được.
Ngoài ra, trực quan hóa dữ liệu đóng vai trò then chốt trong việc thuyết trình, báo cáo, thuyết phục các bên liên quan và đưa ra quyết định kịp thời dựa trên dữ liệu.
Variability (Biến động)
Dữ liệu lớn không chỉ đa dạng mà còn có tính biến động cao, thay đổi liên tục về khối lượng, cấu trúc và tốc độ.
Ví dụ, dữ liệu mạng xã hội có thể tăng đột biến vào các sự kiện nóng; dữ liệu cảm biến IoT có lúc truyền về dồn dập, lúc gián đoạn; hay cấu trúc dữ liệu log có thể thay đổi theo phiên bản ứng dụng.
Tính biến động này đòi hỏi hệ thống Big Data phải đủ linh hoạt, có kiến trúc thiết kế tối ưu và khả năng scalable (mở rộng) để xử lý dữ liệu hiệu quả, duy trì hiệu suất ổn định ngay cả khi khối lượng, định dạng, tốc độ dữ liệu thay đổi bất ngờ.
Ứng dụng của Big Data
Ứng dụng trong kinh doanh và marketing
Trong hai lĩnh vực này, Big Data đóng vai trò then chốt trong việc tìm hiểu khách hàng và tối ưu hóa hoạt động marketing:
- Phân tích hành vi tiêu dùng: Thông qua dữ liệu luồng nhấp chuột, lịch sử mua hàng và hành vi duyệt web, doanh nghiệp có thể xác định mô hình hành vi khách hàng, từ đó thiết kế hành trình phù hợp, tăng tỷ lệ chuyển đổi.
- Cá nhân hóa trải nghiệm: Big Data cho phép tạo ra recommendation engine (hệ thống gợi ý sản phẩm) giống như Amazon hay Shopee, giúp khách hàng nhanh chóng tìm được sản phẩm phù hợp, tăng giá trị đơn hàng.
- Tối ưu chiến dịch marketing: Việc phân tích dữ liệu real-time về hiệu quả quảng cáo trên các kênh (Facebook Ads, Google Ads, TikTok Ads) giúp điều chỉnh nội dung, ngân sách, phân phối kịp thời, đảm bảo tỷ suất lợi nhuận tối đa.
- Dự báo nhu cầu (Demand Forecasting): Big Data kết hợp với AI để dự đoán xu hướng mua hàng trong tương lai, giúp doanh nghiệp quản lý tồn kho, chuỗi cung ứng hiệu quả hơn, giảm chi phí và rủi ro đứt gãy chuỗi cung ứng.
Ứng dụng trong y tế (Healthcare Analytics)
Ngành y tế là một trong những lĩnh vực hưởng lợi lớn nhất từ Big Data nhờ khả năng cải thiện chăm sóc sức khỏe và giảm chi phí điều trị:
- Phân tích hồ sơ bệnh án điện tử (EHR): Cho phép dự đoán bệnh lý, phát hiện sớm bệnh ung thư hoặc các bệnh mãn tính, từ đó nâng cao hiệu quả điều trị và cứu sống bệnh nhân.
- Theo dõi bệnh nhân real-time: Các thiết bị đeo thông minh (như đồng hồ thông minh, vòng tay sức khỏe) kết hợp với Big Data giúp bác sĩ giám sát nhịp tim, huyết áp, chỉ số SpO2,… và đưa ra cảnh báo kịp thời khi phát hiện bất thường.
- Phát hiện dịch bệnh: Phân tích dữ liệu y tế cộng đồng, chẳng hạn như số ca nhập viện, các loại thuốc bán chạy và tần suất tìm kiếm triệu chứng, giúp chính phủ dự báo nguy cơ bùng phát các dịch bệnh như cúm mùa, sốt xuất huyết, hoặc COVID-19.
- Tối ưu hóa vận hành bệnh viện: Dự báo lượng bệnh nhân, quản lý giường bệnh, thiết bị y tế, đội ngũ bác sĩ để đảm bảo vận hành trơn tru và tiết kiệm chi phí.
Ứng dụng trong tài chính (Fraud Detection)
Ngành ngân hàng – tài chính sử dụng Big Data để tăng cường an toàn giao dịch và tối ưu hóa dịch vụ:
- Phát hiện gian lận (Fraud Detection): Hệ thống phân tích Big Data kết hợp machine learning giúp phát hiện các giao dịch bất thường chỉ trong vài mili giây, từ đó chặn kịp thời trước khi gây thiệt hại.
- Chấm điểm tín dụng (Credit Scoring): Bên cạnh lịch sử vay nợ, Big Data còn phân tích các dữ liệu phi truyền thống như hành vi trực tuyến và mức độ sử dụng điện thoại di động để đánh giá mức độ rủi ro tín dụng của khách hàng mới.
- Quản trị rủi ro tài chính (Risk Management): Phân tích dữ liệu thị trường theo thời gian thực giúp ngân hàng và tổ chức tài chính điều chỉnh danh mục đầu tư, giảm thiểu rủi ro trước biến động kinh tế.
Phân tích mạng xã hội
Với hàng tỷ dữ liệu tạo ra mỗi ngày, Big Data giúp doanh nghiệp:
- Phân tích cảm xúc: Đo lường cảm nhận của khách hàng về thương hiệu, sản phẩm, dịch vụ trên Facebook, Twitter, TikTok,…, từ đó điều chỉnh chiến lược truyền thông phù hợp.
- Theo dõi xu hướng (trend analysis): Big Data giúp nhận biết viral content nhanh chóng, hỗ trợ team marketing xây dựng nội dung “bắt trend” kịp thời.
- Influencer analysis: Phân tích dữ liệu hoạt động của KOL/Influencer để chọn gương mặt phù hợp cho từng campaign, tối ưu ngân sách PR.
- Giám sát khủng hoảng truyền thông: Hoạt động lắng nghe mạng xã hội thu thập hàng triệu lượt nhắc đến theo thời gian thực, giúp phát hiện và xử lý khủng hoảng trước khi lan rộng.
Các công nghệ quan trọng của Big Data
Apache Hadoop
Apache Hadoop là framework mã nguồn mở, nền tảng cơ bản nhất trong Big Data. Hadoop cho phép lưu trữ và xử lý dữ liệu theo mô hình phân tán trên hàng trăm, hàng ngàn máy chủ phổ thông (server commodity) với chi phí thấp.
Hệ sinh thái Hadoop bao gồm:
- Hadoop Distributed File System (HDFS): Hệ thống lưu trữ phân tán, chia nhỏ file thành các block, lưu trên nhiều node để tăng tốc độ truy xuất và đảm bảo dự phòng khi một node gặp sự cố.
- MapReduce: Mô hình lập trình xử lý song song, phân chia task thành Map (xử lý dữ liệu) và Reduce (tổng hợp kết quả).
- YARN (Yet Another Resource Negotiator): Module quản lý tài nguyên cluster, điều phối công việc và phân bổ compute resource hợp lý.
- Hadoop Common: Thư viện tiện ích hỗ trợ các module còn lại.
Hadoop giúp doanh nghiệp lưu trữ dữ liệu khổng lồ với chi phí tối ưu, nhưng hạn chế là MapReduce xử lý batch data chậm, không phù hợp phân tích real-time.
Apache Spark
Apache Spark ra đời để khắc phục điểm yếu tốc độ của Hadoop MapReduce. Spark là engine tính toán in-memory, giúp xử lý dữ liệu nhanh gấp nhiều lần MapReduce nhờ hạn chế việc đọc ghi vào đĩa.
Spark hỗ trợ:
- Spark SQL: Xử lý dữ liệu dạng bảng với câu lệnh SQL.
- Spark Streaming: Phân tích dữ liệu streaming real-time từ IoT, logs, social media.
- MLlib: Thư viện machine learning với các thuật toán classification, clustering, regression, collaborative filtering,…
- GraphX: Xử lý dữ liệu đồ thị (graph data) để phân tích mối quan hệ.
Spark có thể chạy độc lập, trên Hadoop YARN hoặc Mesos, và hỗ trợ lập trình đa ngôn ngữ: Scala, Java, Python, R – rất phù hợp cho team Data engineering và Data science.
Data lakes
Data lake là kho lưu trữ dữ liệu lớn ở dạng thô, bao gồm dữ liệu có cấu trúc, bán cấu trúc và không có cấu trúc trong một hệ thống tập trung.
Ưu điểm của Data lakes:
- Lưu trữ mọi loại dữ liệu mà không cần định nghĩa cấu trúc trước.
- Hỗ trợ huấn luyện AI/ML với dữ liệu thô đầy đủ thông tin gốc
- Khả năng mở rộng gần như vô hạn (các hệ thống data lake trên nền tảng đám mây)
- Chi phí rẻ hơn data warehouse, phù hợp lưu trữ dữ liệu dài hạn (long-term archive) hoặc dữ liệu lịch sử.
Data lakes thường được triển khai trên các nền tảng lưu trữ đám mây như Amazon S3, Azure Data Lake Storage, Google Cloud Storage, kết hợp với compute engine (Spark, Presto, Athena) để phân tích khi cần.
NoSQL databases
Khi dữ liệu ngày càng đa dạng, phi cấu trúc, tốc độ thay đổi nhanh và yêu cầu mở rộng theo chiều ngang (scale horizontal), cơ sở dữ liệu NoSQL trở thành giải pháp thay thế RDBMS truyền thống.
Các loại NoSQL phổ biến:
- Document-based: MongoDB, Couchbase (lưu dữ liệu dưới dạng JSON/BSON)
- Column-based: Apache Cassandra, HBase (xử lý dữ liệu khối lượng lớn, tốc độ cao)
- Key-value: Redis, DynamoDB (truy xuất dữ liệu siêu nhanh, caching)
- Graph-based: Neo4j (lưu trữ và phân tích mối quan hệ phức tạp)
Ưu điểm chung của NoSQL là cấu trúc linh hoạt (flexible schema), mở rộng dễ dàng trên nhiều node, phù hợp cho kiến trúc microservices và các ứng dụng real-time.
Đọc chi tiết: Các loại cơ sở dữ liệu NoSQL: Định nghĩa, Ưu – Nhược điểm và Ứng dụng
Google BigQuery, Amazon Redshift
Đây là hai dịch vụ cloud data warehouse nổi bật. Cloud data warehouse là kho dữ liệu được xây dựng trên nền tảng cloud, cho phép lưu trữ và phân tích khối lượng dữ liệu khổng lồ mà không cần quản lý hạ tầng vật lý. Trong bối cảnh Big Data, cloud data warehouse trở nên quan trọng vì:
- Big Data có khối lượng dữ liệu rất lớn (TB, PB) và cần khả năng mở rộng nhanh chóng, điều mà data warehouse truyền thống tại chỗ khó đáp ứng.
- Cloud data warehouse hỗ trợ tách biệt giữa xử lý và lưu trữ, giúp tối ưu chi phí, tăng tốc độ xử lý và dễ dàng mở rộng khi nhu cầu phân tích tăng cao.
- Cho phép chạy các truy vấn phức tạp trên dữ liệu lớn trong thời gian ngắn, phục vụ phân tích dữ liệu thời gian thực và BI.
Google BigQuery: Serverless data warehouse của GCP, hỗ trợ phân tích dữ liệu có quy mô petabyte bằng SQL với chi phí tính theo query, không cần quản lý hạ tầng.
Amazon Redshift: Dịch vụ data warehouse trên AWS, cho phép chạy SQL query nhanh, tích hợp tốt với hệ sinh thái AWS và các công cụ BI.
Cả BigQuery và Redshift đều hỗ trợ:
- Khả năng xử lý đồng thời cao (High concurrency): Hàng trăm đến hàng ngàn user chạy query đồng thời.
- Việc lưu trữ và tính toán có thể mở rộng theo nhu cầu thực tế.
- Khả năng tích hợp mạnh mẽ với các công cụ BI (Tableau, Power BI) và pipeline ETL.
Tương lai của Big Data
Big Data sẽ tiếp tục là trung tâm chiến lược của mọi tổ chức trong thập kỷ tới, khi khối lượng dữ liệu toàn cầu dự kiến sẽ tăng gấp nhiều lần. Theo báo cáo của IDC, lượng dữ liệu toàn cầu có thể đạt hơn 175 zettabyte vào năm 2025, cho thấy nhu cầu phân tích và khai thác giá trị từ dữ liệu sẽ ngày càng cấp thiết. Điều này không chỉ thay đổi cách các tập đoàn công nghệ vận hành, mà còn định hình cách mọi doanh nghiệp đưa ra quyết định.
Dưới đây là 4 xu hướng chính sẽ dẫn dắt tương lai của Big Data:
Điện toán đám mây (Cloud computing)
Cloud computing đang trở thành lựa chọn mặc định cho lưu trữ và xử lý Big Data nhờ những ưu điểm vượt trội:
- Tính linh hoạt: Doanh nghiệp có thể dễ dàng mở rộng hoặc thu hẹp (scale up/down) tài nguyên lưu trữ và tính toán theo nhu cầu thực tế, mà không bị giới hạn bởi hạ tầng vật lý.
- Tiết kiệm chi phí: Mô hình pay-as-you-go giúp cắt giảm đáng kể chi phí đầu tư ban đầu (CAPEX), doanh nghiệp chỉ phải trả tiền cho đúng tài nguyên đã sử dụng (OPEX).
- Triển khai nhanh chóng: Việc khởi tạo data warehouse, data lake hoặc cluster Spark/Hadoop có thể thực hiện chỉ trong vài phút, thay vì mất hàng tuần hoặc hàng tháng như với mô hình on-premise.
Với các nền tảng như AWS, Google Cloud và Azure, doanh nghiệp có thể dễ dàng triển khai pipeline Big Data hoàn chỉnh trên đám mây, phục vụ phân tích, Machine Learning và AI mà không cần lo lắng về việc quản lý hạ tầng phức tạp.
Theo Gartner, đến năm 2025, 85% doanh nghiệp sẽ ưu tiên kiến trúc cloud-first cho Big Data và phân tích. Vì vậy, nếu bạn muốn bắt kịp xu hướng, hãy bắt đầu tìm hiểu các dịch vụ Big Data trên cloud (AWS, GCP, Azure), cũng như thành thạo SQL trên cloud data warehouse (BigQuery, Redshift) để mở rộng cơ hội nghề nghiệp trong lĩnh vực dữ liệu.
IoT (Internet of Things)
IoT sẽ tiếp tục tạo ra khối lượng dữ liệu khổng lồ, vượt xa khả năng xử lý của các hệ thống truyền thống. Theo IDC, đến năm 2026, dữ liệu tạo ra từ các thiết bị IoT có thể đạt tới 90 zettabyte, chiếm phần lớn tổng dữ liệu toàn cầu, đặc biệt đến từ camera an ninh, cảm biến công nghiệp và thiết bị đeo tay y tế.
Các thiết bị IoT như sensor trong nhà máy, camera giám sát, xe tự lái, drone logistics, smartwatch liên tục tạo ra dữ liệu streaming real-time, đòi hỏi hệ thống Big Data có thể xử lý và phân tích ngay lập tức. Đây là lý do edge computing trở nên quan trọng, khi dữ liệu được xử lý trực tiếp tại thiết bị hoặc edge server thay vì gửi toàn bộ lên cloud, giúp giảm độ trễ (latency) và tiết kiệm băng thông.
Phân tích dữ liệu IoT đang mở ra vô số ứng dụng trong smart city (thành phố thông minh), smart factory (nhà máy thông minh), healthcare monitoring (giám sát y tế từ xa) và tối ưu hóa logistics.
Nếu bạn muốn phát triển sự nghiệp trong Big Data và IoT, hãy bắt đầu học về:
- Streaming data processing: Apache Kafka, Spark Streaming
- Kiến trúc điện toán biên (edge computing): Hiểu cách kết hợp edge + cloud để xử lý dữ liệu IoT hiệu quả.
- Kỹ năng triển khai pipeline thời gian thực.
Bảo mật & riêng tư
Khi dữ liệu cá nhân và doanh nghiệp ngày càng nhiều, bảo mật và quyền riêng tư sẽ trở thành ưu tiên hàng đầu:
- Data privacy: Doanh nghiệp bắt buộc phải tuân thủ các quy định GDPR, CCPA, PDP, đảm bảo minh bạch trong việc thu thập, lưu trữ và xử lý dữ liệu người dùng.
- Data security: Hệ thống phải được thiết kế với cơ chế bảo mật nhiều lớp, bao gồm mã hóa (encryption) khi lưu trữ và truyền tải, quản lý quyền truy cập (IAM) và giám sát liên tục.
- Data governance: Quản trị dữ liệu chặt chẽ nhằm đảm bảo chất lượng dữ liệu, khả năng truy xuất nguồn gốc (lineage), kiểm tra và đối soát (audit trail) rõ ràng.
Trong thế giới Big Data, doanh nghiệp nào đảm bảo được bảo mật và tuân thủ sẽ tạo dựng được niềm tin vững chắc với khách hàng. Để làm được điều đó, bạn nên:
- Nâng cao kỹ năng Data Governance và encryption trên Cloud.
- Lấy các chứng chỉ về bảo mật như CISSP, AWS Security, hoặc tìm hiểu thêm về privacy frameworks.
Học máy tích hợp sâu hơn (Machine Learning)
Trong tương lai, Machine Learning (ML) sẽ được tích hợp sâu vào pipeline Big Data, trở thành công cụ không thể thiếu để doanh nghiệp khai thác giá trị thực sự từ dữ liệu. Theo Acceldata (2023), AI và ML sẽ không còn là lựa chọn mà trở thành yếu tố bắt buộc, giúp các tổ chức chuyển đổi từ descriptive analytics (phân tích mô tả) sang predictive analytics (dự báo) và prescriptive analytics (đề xuất hành động).
ML sẽ đóng vai trò then chốt trong:
- Dự đoán nhu cầu khách hàng: Giúp tối ưu tồn kho, marketing, personalisation.
- Phát hiện gian lận: Đặc biệt trong ngành tài chính – ngân hàng, bảo hiểm.
- Tối ưu chuỗi cung ứng: Dự báo supply-demand để giảm tồn kho hoặc đứt gãy.
- Recommendation systems: Gợi ý sản phẩm phù hợp, tăng conversion rate.
Bên cạnh đó, MLOps (Machine Learning Operations) sẽ trở thành kỹ năng bắt buộc, giúp team dữ liệu triển khai, theo dõi và thực hiện việc huấn luyện lại các mô hình ML liên tục, đảm bảo độ chính xác và hiệu quả lâu dài trong môi trường production. Vì vậy, việc thành thạo lập trình Python cùng nền tảng ML vững chắc (như scikit-learn, TensorFlow, PyTorch) là điều không thể thiếu nếu bạn muốn phát triển sự nghiệp trong lĩnh vực Big Data và AI.
Các câu hỏi thường gặp về Big Data là gì
Big Data có phù hợp với doanh nghiệp vừa và nhỏ không?
Có, nhưng cần cách tiếp cận phù hợp.
Nhiều doanh nghiệp SME thường nghĩ Big Data chỉ dành cho tập đoàn lớn do yêu cầu hạ tầng phức tạp và chi phí cao. Tuy nhiên, với sự phát triển của cloud computing và các dịch vụ Big Data-as-a-Service, doanh nghiệp vừa và nhỏ hoàn toàn có thể tận dụng Big Data mà không cần đầu tư server đắt đỏ.
Thay vì triển khai toàn bộ hệ sinh thái Hadoop hoặc Spark on-premise, SMEs có thể bắt đầu bằng các bài toán nhỏ, thiết thực như phân tích hành vi khách hàng, tối ưu tồn kho, dự báo doanh số, sử dụng các giải pháp trên cloud như Google BigQuery, Amazon Redshift theo mô hình pay-as-you-go, chỉ trả phí cho tài nguyên đã sử dụng.
Bên cạnh đó, SMEs có thể thuê ngoài chuyên gia hoặc data consultant để triển khai giải pháp nhanh gọn mà vẫn đảm bảo hiệu quả. Big Data nếu được triển khai đúng cách sẽ giúp doanh nghiệp vừa và nhỏ hiểu khách hàng sâu hơn, tối ưu vận hành và ra quyết định chính xác, từ đó nâng cao năng lực cạnh tranh ngay cả khi ngân sách còn hạn chế.
Lương của Big Data Engineer có cao không?
Câu trả lời là có.
Theo Báo cáo Lương IT 2024-2025 của ITviec, nhóm Big Data và Data Engineer hiện đang nằm trong nhóm công việc có thu nhập cao ở ngành IT.
Mặc dù báo cáo chưa tách Big Data Engineer thành nhóm riêng, nhưng thực tế, đây là nhánh chuyên sâu của Data Engineer và thường có mức lương cao hơn khoảng 10–20% nhờ yêu cầu kỹ năng nâng cao về hạ tầng xử lý dữ liệu phân tán (Hadoop, Spark, NoSQL, Data Lake), cũng như khả năng thiết kế hệ thống Big Data end-to-end tối ưu, đảm bảo độ tin cậy cao:
| Khoảng năm kinh nghiệm | Data Engineer | Big Data Engineer |
| < 2 years | 20–30 triệu | 23–35 triệu |
| 2 – 4 years | 30–50 triệu | 35–57 triệu |
| 4 – 6 years | 50–65 triệu | 55–75 triệu |
| >6 years | 80 triệu+ | 90 triệu+ |
Nhìn chung, với dưới 2 năm kinh nghiệm, Big Data Engineer đã có thu nhập từ 23–35 triệu đồng/tháng, và khi đạt trên 6 năm kinh nghiệm, mức lương thường từ 90 triệu đồng/tháng trở lên, phản ánh giá trị lớn mà họ mang lại cho doanh nghiệp trong việc xây dựng hệ thống dữ liệu mạnh mẽ, sẵn sàng phục vụ phân tích AI/ML và real-time analytics.
Đây là một lựa chọn nghề nghiệp tiềm năng cho các kỹ sư dữ liệu muốn phát triển chuyên sâu về Big Data và Cloud.
Học Big Data có cần kiến thức nền tảng lập trình không?
Rất cần thiết. Để làm việc với Big Data, bạn bắt buộc phải có kiến thức nền tảng lập trình, đặc biệt là các ngôn ngữ phổ biến như Python, Java hoặc Scala.
Lập trình giúp bạn viết các pipeline xử lý dữ liệu, thao tác với framework phân tán (Apache Spark, Hadoop), truy vấn dữ liệu bằng SQL hoặc NoSQL, và tự động hóa các quy trình ETL. Ngoài ra, khi làm việc với Big Data, bạn cũng cần hiểu cách viết script để thao tác dữ liệu trên cloud, sử dụng API hoặc tích hợp với các hệ thống khác.
Không nhất thiết phải giỏi ngay từ đầu, những việc nắm chắc lập trình cơ bản sẽ giúp bạn học nhanh hơn, triển khai giải pháp thực tế hiệu quả hơn và dễ dàng phát triển lên các vị trí chuyên sâu như Data Engineer hoặc Big Data Engineer.
Gợi ý: Nếu bạn chưa có nền tảng lập trình, hãy bắt đầu học Python hoặc Java, đồng thời luyện tập SQL song song trước khi bước vào các công nghệ Big Data.
Tổng kết Big Data là gì
Big Data không chỉ là khối lượng dữ liệu khổng lồ, mà còn là cách chúng ta khai thác, xử lý và biến dữ liệu thành giá trị thực tiễn. Trong thời đại số, Big Data giúp doanh nghiệp hiểu rõ khách hàng, tối ưu vận hành, dự đoán xu hướng và ra quyết định chính xác hơn, tạo lợi thế cạnh tranh bền vững trên thị trường.
Với sự phát triển mạnh mẽ của cloud computing, IoT và machine learning, Big Data sẽ tiếp tục giữ vai trò trung tâm trong chiến lược chuyển đổi số của mọi tổ chức, từ startup đến tập đoàn đa quốc gia. Để làm việc hiệu quả với Big Data, bạn cần trang bị nền tảng lập trình, SQL, kiến thức về hệ thống phân tán và tư duy dữ liệu, khi đó bạn sẽ có cơ hội nghề nghiệp rộng mở trong lĩnh vực data đang tăng trưởng mạnh mẽ hiện nay.
