
Với vị trí Fullstack Developer, bạn sẽ phụ trách cả mảng Frontend (UX/UI, flow) và Backend (database, API) của trang web hoặc ứng dụng. Điều này đòi hỏi bạn vừa phải có kiến thức chuyên sâu cả 2 mảng, vừa nhạy bén ứng biến linh hoạt với từng công cụ lập trình. Trong bài viết này, ITviec sẽ tổng hợp các câu hỏi phỏng vấn Fullstack Developer thường gặp bao gồm cả kiến thức và xử lý tình huống.
Đọc bài viết để hiểu rõ hơn về:
- Fullstack Developer thực hiện những công việc gì?
- Câu hỏi phỏng vấn Fullstack Developer cho cấp đầu vào
- Câu hỏi phỏng vấn Fullstack Developer cho cấp trung
- Câu hỏi phỏng vấn Fullstack Developer cho cấp chuyên nghiệp
Fullstack Developer thực hiện những công việc gì?
Các Fullstack Developer là những chuyên gia lập trình có khả năng thực hiện cả các nhiệm vụ Frontend (phần giao diện người dùng) và Backend (phần logic xử lý phía máy chủ) trong một dự án phần mềm. Nói cách khác, họ là những người “tất cả trong một” có thể xây dựng một ứng dụng web hoặc ứng dụng di động từ đầu đến cuối.
Công việc hàng ngày của một Fullstack Developer có thể là:
- Phát triển và duy trì các dịch vụ, giao diện web
- Xây dựng các tính năng hoặc API cho sản phẩm mới
- Kiểm tra, khắc phục sự cố phần mềm và sửa lỗi
- Hướng dẫn công việc cho các đồng nghiệp cấp dưới (đối với các Fullstack Developer từ cấp trung trở lên)
- Cập nhật các thông tin, kiến thức mới phục vụ cho công việc
Theo báo cáo Báo Cáo Lương & Thị Trường Tuyển Dụng IT 2024 – 2025 tại Việt Nam từ ITviec, một Fullstack Developer có thể có mức lương trung vị theo số năm kinh nghiệm như sau:
- <1 năm kinh nghiệm: 14.200.000đ/ tháng
- 1 – 2 năm kinh nghiệm: 16.650.000đ /tháng
- 3 – 4 năm kinh nghiệm: 29.900.000đ/ tháng
- 5 – 8 năm kinh nghiệm: 39.700.000đ/ tháng
- >8 năm kinh nghiệm: 50.000.000đ/ tháng
Lưu ý, mức lương này chưa bao gồm các khoản hỗ trợ khác từ Công ty (nếu có).
Câu hỏi phỏng vấn Fullstack Developer đầu vào (Fresher / Junior Fullstack Devloper)
Frontend và Backend có gì khác nhau?
Lập trình Frontend: Tập trung vào các yếu tố trực quan và tương tác của người dùng trên trang web hoặc ứng dụng. Các công nghệ được sử dụng bao gồm HTML, CSS và JavaScript để tạo giao diện người dùng và trải nghiệm người dùng (UI/UX).
Lập trình Backend: Tập trung vào việc xử lý logic phía máy chủ, cơ sở dữ liệu và API (giao diện lập trình ứng dụng), cung cấp năng lượng cho chức năng của trang web. Python, Ruby, PHP, Node.js,… là các ngôn ngữ lập trình chính của Backend Developer.
Sự khác biệt giữa Frontend và Backend có thể xét dựa trên các tiêu chí sau:
| Tiêu chí | Frontend | Backend |
| Ngôn ngữ thường dùng | HTML, CSS, JavaScript | Java, Python, Ruby, PHP, Node.js |
| Tập trung | Giao diện người dùng và trải nghiệm | Logic máy chủ, cơ sở dữ liệu, API và hiệu suất của ứng dụng |
| Thư viện / Framework thường dùng | React, Angular, Vue.js, Bootstrap | Django, Express, Ruby on Rails, Spring |
| Vai trò | Thiết kế, bố cục (layout) và khả năng phản hồi (responsive) của UI | Xử lý dữ liệu, logic phía máy chủ, bảo mật ứng dụng |
| Khả năng tiếp cận | Là giao diện mà người dùng tương tác trực tiếp | Không thể tiếp cận trực tiếp; tương tác thông qua giao diện |
| Objective | Giao diện và cảm nhận của ứng dụng | Chức năng, bảo mật và hiệu suất |
| Công cụ | Trình duyệt (browser), thư viện giao diện (frontend libraby) | Máy chủ (server), cơ sở dữ liệu (database), khung nền tảng (backend framework) |
| Kiểm tra (testing) | Trải nghiệm người dùng, bố cục, khả năng phản hồi | Kiểm thử phía máy chủ (server-side testing), API endpoints, logic |
Đọc thêm: Front End vs Back End: Khác nhau và Hỗ trợ nhau như thế nào?
Đa luồng (multithreading) là gì?
Luồng (thread) là một phần hoặc đơn vị độc lập của một tiến trình (hoặc ứng dụng) đang được thực thi. Khi có nhiều luồng chạy đồng thời trong một tiến trình, chúng ta gọi đó là “đa luồng” (multithreading).
Sử dụng đa luồng mang lại nhiều lợi ích về hiệu suất và chi phí hơn nhờ các ưu điểm như: Tối ưu được nguồn tài nguyên, tăng tốc độ phản hồi của ứng dụng, giảm thiểu được rủi ro, quản lý hiệu quả nguồn dữ liệu.
Hãy kể tên các công cụ và công nghệ thường dùng để lập trình full stack mà bạn biết
Công cụ và công nghệ lập trình Frontend
| Framework và Thư viện | React, Angular, VueJS, Svelte |
| CSS Framework | Bootstrap, Tailwind CSS, Foundation |
| State Management ( | Redux, Vuex |
| Package Managers (Trình quản lý gói) | npm, yarn |
| Preprocessors (Bộ tiền xử lý) | Sass, Less |
| Browser Debugging Tools (Công cụ gỡ lỗi trình duyệt) | Chrome Dev Tools, Firefox Developer Tools |
Công cụ và công nghệ lập trình Backend
| Ngôn ngữ lập trình | JavaScript (Node.js), Python, Java, Ruby, PHP, Go |
| Frameworks | Express.js (Node.js), Django (Python), Flask (Python), Spring Boot (Java), Ruby on Rails (Ruby), Laravel (PHP), ASP.NET (C#) |
| API Development and Documentation | Swagger / OpenAPI, Postman, GraphQL |
| Authentication and Authorization (Xác thực và uỷ quyền) | OAuth2, JWT (JSON Web Tokens), Passport.js |
| Database Management System (Hệ thống quản lý cơ sở dữ liệu) | – Relational Databases: MySQL, PostgreSQL, SQLite, Microsoft SQL Server
– NoSQL Databases: MongoDB, Redis, Cassandra, Firebase |
| Build and Deployment Tools (Công cụ xây dựng và triển khai) | – Build Tools (Công cụ xây dựng): Maven (Java), Gradle (Java, Kotlin), Gulp (JavaScript), Grunt (JavaScript)
– Containerization and Orchestration (Container hoá và điều phối): Docker, Kubernetes – CI/CD Tools: Jenkins, GitLab CI/CD, Azure DevOps |
Lập trình cặp (pair programming) là gì?
Lập trình cặp (pair programming) là một phương pháp lập trình mà hai lập trình viên có thể viết code trên duy nhất một máy tính.
Trong đó, một lập trình viên sẽ đóng vai trò là driver – người viết code chính, lập trình viên còn lại chịu trách nhiệm giám sát (navigator), kiểm tra, sửa lỗi thậm chí là định hướng những bước cần làm tiếp theo. Vai trò của cả hai lập trình viên có thể thay đổi cho nhau.
Theo bạn, CORS (Cross-Origin Resource Sharing) có ý nghĩa gì trong lập trình Fullstack?
CORS (Cross-Origin Resource Sharing) đề cập đến việc chia sẻ tài nguyên giữa các nguồn. Đây là một cơ chế trình duyệt cho phép các trang web trong một miền có quyền truy cập vào các tài nguyên trong các miền khác. Các lập trình viên có thể kết hợp CORS với các tập lệnh web khi cần kết nối với miền, giao thức hoặc cổng bên ngoài. Điều này thường cần thiết khi các ứng dụng web frontend (chạy trên trình duyệt) cần gọi các API từ backend (chạy trên máy chủ khác).
CORS hoạt động bằng cách sử dụng các tiêu đề HTTP để thông báo với trình duyệt rằng một trang web tại một nguồn (origin) cụ thể có quyền truy cập vào tài nguyên tại một nguồn khác.
JavaScript Promise trong lập trình Fullstack là gì?
Promise trong JavaScript giống như một “hộp chứa” cho một giá trị sẽ có trong tương lai. Giống như việc bạn đặt mua một cuốn sách trên Shopee nhưng phải chờ 3 – 4 ngày nữa mới nhận được. Trong lúc chờ đợi, bạn đã đọc một cuốn sách khác. Cho đến khi sách đến, bạn mới bắt đầu đọc.
Tương tự như trong lập trình Fullstack, Promise cho phép bạn tiếp tục viết và điều chỉnh code trong khi chờ đợi một thao tác khác hoàn thành, chẳng hạn tải dữ liệu từ máy chủ. Khi dữ liệu sẵn sàng, Promise sẽ cung cấp nó cho bạn.
Promise và Callback Hell có gì khác nhau?
| Callback | Promise |
| Cú pháp khó hiểu | Cú pháp thân thiện và dễ đọc vì có then và catch |
| Khó quản lý trong việc xử lý lỗi | Dễ quản lý trong việc xử lý lỗi khi sử dụng khối catch |
| Có thể tạo ra callback hell | Giải quyết callback hell |
| Code khó đọc, khó bảo trì | Giảm thiểu code lồng nhau |
Short polling và Long polling có nghĩa là gì?
Short Polling là một kỹ thuật mà trong đó, máy khách yêu cầu dữ liệu từ máy chủ và máy chủ sẽ trả về phản hồi nếu dữ liệu có sẵn. Trong trường hợp dữ liệu không có sẵn, máy chủ sẽ trả về phản hồi trống. Quá trình này sẽ được lặp lại theo các khoảng thời gian đều đặn.
Ngược lại, Long Polling là kỹ thuật được sử dụng để đẩy thông tin/dữ liệu từ máy chủ đến máy khách nhanh nhất có thể. Khi máy khách gửi yêu cầu đến máy chủ, long-polling duy trì kết nối giữa hai máy. Kết nối này được duy trì cho đến khi thông tin sẵn sàng được gửi từ máy chủ đến máy khách. Kết nối chỉ đóng khi máy chủ đã gửi dữ liệu trở lại máy khách hoặc khi đạt đến ngưỡng thời gian chờ.
Hãy cho biết sự khác nhau giữa GraphQL và REST
| GraphQL | REST |
| Ngôn ngữ truy vấn, cho phép truy xuất dữ liệu khai báo để cung cấp cho khách hàng quyền kiểm soát dữ liệu nào sẽ truy xuất từ API. | Kiểu kiến trúc thiết kế API xác định một tập hợp các ràng buộc để tạo dịch vụ web. |
| Các truy vấn GraphQL đưa ra kết quả có thể dự đoán được, giúp cải thiện đáng kể khả năng sử dụng. | Hành vi của REST phụ thuộc vào các phương thức HTTP và URI được sử dụng. |
| Có thể đảm bảo bảo mật API, mặc dù các tính năng bảo mật không hoàn thiện như REST | Có thể triển khai nhiều phương thức xác thực API, chẳng hạn xác thực HTTP, để đảm bảo bảo mật REST API. |
| Có thể truy xuất mọi thứ bạn cần thông qua một yêu cầu API duy nhất.
Có thể chỉ định cấu trúc thông tin bạn cần và máy chủ sẽ trả về cùng một cấu trúc. |
Vì REST API có cấu trúc dữ liệu cứng nhắc nên dữ liệu trả về có thể không theo những gì bạn mong muốn hoặc bạn phải thực hiện rất nhiều yêu cầu để nhận được dữ liệu phù hợp. |
| Chỉ hỗ trợ định dạng JSON. | XML, YAML, JSON, HTML và các định dạng khác cũng được hỗ trợ. |
| Chủ yếu được sử dụng cho các ứng dụng di động và nhiều dịch vụ vi mô. | Chủ yếu được sử dụng cho các ứng dụng đơn giản và các ứng dụng dựa trên tài nguyên. |
Hoisting là gì?
Hoisting là hành vi mặc định trong JavaScript. Trong đó các khai báo biến và hàm được di chuyển lên đầu phạm vi tương ứng của chúng trong giai đoạn biên dịch. Điều này đảm bảo rằng bất kể các khai báo này xuất hiện ở đâu trong phạm vi, chúng đều có thể được truy cập trong phạm vi đó.
- Khi bạn khai báo một biến bằng var, khai báo này sẽ được đưa lên đầu phạm vi chức năng hoặc phạm vi toàn cục. Tuy nhiên, việc gán giá trị cho biến đó không bị hoisted.
- Khai báo biến bằng let và const cũng được hoisted nhưng chúng không được khởi tạo. Điều này có nghĩa là bạn không thể truy cập chúng trước khi dòng mã khai báo thực thi.
Tích hợp liên tục (CI) là gì?
CI là quá trình tự động hóa và tích hợp các thay đổi code vào một dự án phần mềm duy nhất, thường là nhiều lần trong ngày. Mục đích của hoạt động DevOps này là cho phép các lập trình viên hợp nhất các thay đổi trên code vào một kho lưu trữ trung tâm. Các công cụ tự động được sử dụng để đảm bảo code mới chính xác trước khi được tích hợp.
Trong quy trình CI, hệ thống kiểm soát phiên bản mã nguồn đóng vai trò cốt lõi. Bên cạnh đó, quy trình còn được hỗ trợ bởi các công cụ kiểm tra tự động khác như kiểm tra chất lượng code, đánh giá cú pháp và các bước kiểm duyệt khác.
Đọc thêm: CI/CD là gì? Lợi ích và các nguyên tắc triển khai CI/CD
Bạn hiểu thế nào về ACID trong cơ sở hệ thống dữ liệu?
ACID là một tập hợp các thuộc tính chuẩn, đảm bảo các giao dịch trên cơ sở dữ liệu diễn ra một cách chính xác. Nếu một hoạt động cơ sở dữ liệu đáp ứng các thuộc tính này, thì nó được gọi là giao dịch ACID. Các hệ thống cơ sở dữ liệu áp dụng các thuộc tính này được gọi là hệ thống giao dịch.
- Atomicity: Đảm bảo toàn bộ giao dịch diễn ra như một đơn vị duy nhất.
- Consistency: Cơ sở dữ liệu vẫn nhất quán do một giao dịch.
- Isolation: Nhiều giao dịch có thể diễn ra độc lập mà không có bất kỳ sự can thiệp nào.
- Durability: Ngay cả khi hệ thống bị lỗi, giao dịch đã cam kết vẫn không thay đổi.
Các tính năng chính của MongoDB là gì?
MongoDB là một cơ sở dữ liệu phi quan hệ. Mô hình linh hoạt của MongoDB lưu trữ dữ liệu phi cấu trúc và cung cấp hỗ trợ lập chỉ mục đầy đủ.
Các tính năng chính của MongoDB là:
- Truy vấn tùy ý: Hỗ trợ các truy vấn khác nhau, chẳng hạn truy vấn trường, phạm vi và biểu thức chính quy. Có thể sử dụng các truy vấn này để trả về các phần của tài liệu hoặc toàn bộ tài liệu.
- Sao chép: Cung cấp tính khả dụng cao của các bộ bản sao.
- Lập chỉ mục (Index): Có thể sử dụng các chỉ mục chính và phụ để lập chỉ mục các trường của tài liệu được lưu trữ trong cơ sở dữ liệu MongoDB.
- Lưu trữ dữ liệu lớn: MongoDB có thể xử lý các tập dữ liệu lớn một cách hiệu quả, nhờ vào khả năng phân mảnh dữ liệu và lưu trữ trên nhiều máy chủ.
- Cân bằng tải: Tự động phân phối tải làm việc giữa các máy chủ trong cụm, đảm bảo hiệu suất cao và khả năng mở rộng.
- Lưu trữ dữ liệu lớn: MongoDB có thể xử lý các tập dữ liệu lớn một cách hiệu quả, nhờ vào khả năng phân mảnh dữ liệu và lưu trữ trên nhiều máy chủ.
Câu hỏi phỏng vấn Fullstack Developer trung cấp (Middle Fullstack Developer)
Express.js là gì?
Express.js là một framework (khung làm việc) backend được xây dựng trên nền tảng Node.js. Nó cung cấp một cấu trúc và các công cụ cần thiết để giúp các nhà phát triển xây dựng các ứng dụng web và API một cách nhanh chóng và hiệu quả.
Làm thế nào để dùng calc() trong Tailwind CSS?
calc() là một hàm tích hợp trong CSS cho phép bạn thực hiện các phép tính toán học. Bạn có thể sử dụng hàm calc() trong Tailwind CSS để xác định giá trị động cho các thuộc tính CSS khác nhau.
Một số cách sử dụng calc() trong Tailwind CSS:
- Sử dụng calc( ) bên trong HTML bằng cách sử dụng tailwind CSS làm kiểu nội tuyến (Inline Style).
- Thêm các lớp tùy chỉnh hoặc mở rộng cấu hình Tailwind để tái sử dụng nhiều hơn trên nhiều phần tử.
- Mở rộng chủ đề Tailwind hoặc sử dụng các tiện ích tùy chỉnh trong tệp tailwind.config.js.
- Định nghĩa một lớp CSS tùy chỉnh bằng calc() và áp dụng nó cùng với các tiện ích của Tailwind.
Đọc thêm: Tailwind CSS: Hướng dẫn 3 cách thiết lập Tailwind chi tiết
Nêu sự khác biệt giữa Server-side Scripting và Client-side Scripting
| Tiêu chí | Server-side Scripting | Client-side Scripting |
| Lĩnh vực tập trung | Backend | Frontend |
| Xử lý | Cầu nối giữa client và cơ sở dữ liệu, xử lý các yêu cầu từ client và trả về kết quả. | Có thể thực hiện các yêu cầu AJAX để tương tác với máy chủ. |
| Ngôn ngữ hỗ trợ | Ruby, ASP.net, PHP và Python,… | CSS, JavaScript, HTML,… |
| Tính bảo mật | Cao | Thấp |
| Khả năng hiển thị | Người dùng không thể xem mã nguồn | Mã nguồn hiển thị với người dùng. Tuy nhiên, có thể minify hoặc obfuscate để khó đọc hơn. |
| Chức năng | Cung cấp đầu ra theo yêu cầu cho người dùng cuối | Thao tác và cho phép truy cập vào cơ sở dữ liệu |
Làm thế nào để thực hiện lệnh gọi từ AJAX?
Thực hiện lệnh gọi Ajax từ JavaScript có nghĩa là gửi yêu cầu không đồng bộ đến máy chủ để lấy hoặc gửi dữ liệu mà không cần tải lại trang web. Điều này cho phép cập nhật nội dung động, nâng cao trải nghiệm người dùng bằng cách làm cho ứng dụng web tương tác và phản hồi hơn.
Có 3 cách thực hiện lệnh gọi từ AJAX:
- Cách 1: Sử dụng đối tượng XMLHttpRequest để thực hiện lệnh gọi Ajax. Phương thức XMLHttpRequest() tạo ra một đối tượng XMLHttpRequest được sử dụng để thực hiện yêu cầu với máy chủ.
- Cách 2: Phương thức ajax() được sử dụng trong jQuery để thực hiện lệnh gọi ajax. Phương thức này được sử dụng để thay thế cho tất cả các cách tiếp cận không thực hiện được lệnh gọi ajax.
- Cách 3: Sử dụng API fetch() để tạo XMLHttpRequest với máy chủ. API này tạo một yêu cầu đến máy chủ và nhận kết quả dưới dạng một lời hứa được giải quyết thành chuỗi.
Ngoài jQuery và Fetch API, còn có nhiều thư viện khác như Axios, Superagent, … mỗi thư viện có những ưu điểm và cách sử dụng riêng.
Đọc thêm: AJAX là gì? Quy trình hoạt động và thực hành AJAX dễ hiểu cho Web Developer
Nêu sự khác biệt giữa chuẩn hóa (normalization) và phi chuẩn hóa (denormalization)
| Tiêu chí | Normalization | Denormalization |
| Hoạt động | Loại bỏ dữ liệu dư thừa (nhiều bản sao dữ liệu) khỏi cơ sở dữ liệu và lưu trữ dữ liệu nhất quán, không dư thừa | Kết hợp dữ liệu từ nhiều bảng thành một bảng duy nhất để có thể truy vấn nhanh chóng. |
| Mục tiêu | Chủ yếu tập trung vào việc xóa dữ liệu không sử dụng và giảm dữ liệu trùng lặp và không nhất quán từ cơ sở dữ liệu | Đạt được tốc độ thực hiện truy vấn nhanh hơn bằng cách thêm dữ liệu dự phòng |
| Số lượng bảng | Số lượng bảng giảm do dữ liệu trong cơ sở dữ liệu giảm | Tích hợp dữ liệu vào cùng một cơ sở dữ liệu nên số lượng bảng để lưu trữ dữ liệu tăng lên |
| Tính toàn vẹn | Được duy trì bằng chuẩn hóa. Một thay đổi đối với dữ liệu trong bảng sẽ không ảnh hưởng đến mối quan hệ của nó với bảng khác. | Không được duy trì bằng phi chuẩn hóa |
| Không gian đĩa | Được tối ưu hóa | Không được tối ưu hóa |
Làm thế nào để truy cập lịch sử trong JavaScript?
Object History (lịch sử đối tượng) chứa lịch sử của trình duyệt. URL của các trang mà người dùng đã truy cập được lưu trữ dưới dạng ngăn xếp trong object history. Có nhiều phương pháp để quản lý/truy cập lịch sử.
Các phương pháp của Object History:
Phương pháp forward()
Được sử dụng để tải URL tiếp theo trong danh sách history. Phương pháp này có chức năng giống hệt như nút next trong trình duyệt. Cú pháp:
history.forward()
Phương pháp back()
Được sử dụng để tải URL trước đó trong danh sách history. Phương pháp này có chức năng giống hệt như nút back trong trình duyệt. Cú pháp:
history.back()
Phương pháp go()
Được sử dụng để tải URL từ danh sách history. Cú pháp:
history.go(integer)
Làm thế nào để chuyển hướng đến một trang web khác bằng JavaScript?
JavaScript có thể chuyển hướng người dùng từ trang hiện tại sang một trang web khác (URL khác). Để chuyển hướng đến một trang web khác, lập trình viên cần thao tác đối tượng window.location và đối tượng này sẽ cho phép điều hướng theo chương trình.
Các cách chuyển hướng đến một trang web khác bằng JavaScript:
Sử dụng window.location.href để đặt hoặc trả về URL đầy đủ của trang hiện tại.
Thuộc tính này cũng có thể được sử dụng để đặt giá trị href trỏ đến một trang web khác, một địa chỉ email hoặc trả về một chuỗi chứa toàn bộ URL của trang, bao gồm cả giao thức. Cú pháp:
window.location.href = "URL"
Sử dụng phương thức location.replace() để thay thế tài liệu hiện tại bằng tài liệu đã chỉ định.
Phương thức này khác với phương thức assignment() vì nó xóa tài liệu hiện tại khỏi lịch sử tài liệu, do đó không thể quay lại tài liệu trước đó bằng nút back. Cú pháp:
location.replace("URL");
Làm thế nào để ngăn chặn bot thu thập dữ liệu từ API có thể truy cập công khai?
Nếu dữ liệu của API có sẵn công khai, khó có thể ngăn bot thu thập dữ liệu. Tuy nhiên, có thể sử dụng phương pháp điều tiết hoặc giới hạn tốc độ để khắc phục sự cố này.
Điều tiết là phương pháp ngăn thiết bị thực hiện một số lượng yêu cầu xác định trong một khoảng thời gian xác định. Khi số lượng yêu cầu vượt quá số lượng đã chỉ định, lỗi HTTP sẽ được đưa ra.
Yêu cầu người dùng đăng nhập hoặc sử dụng API key để xác thực danh tính, giúp hạn chế các yêu cầu đến từ các nguồn không xác định.
Bạn thực hiện các hoạt động CRUD trong MongoDB như thế nào?
CRUD là viết tắt của Create, Read, Update và Delete.
Mongoose, một thư viện Object Data Modeling (ODM) dành cho MongoDB, đơn giản hóa các thao tác này bằng cách cung cấp một giao diện quen thuộc tương tự như khi làm việc với các đối tượng trong JavaScript.
Có thể sử dụng các phương thức Mongoose để tạo tài liệu mới, tìm tài liệu hiện có, cập nhật dữ liệu và xóa tài liệu khỏi cơ sở dữ liệu MongoDB.
Git và Github có điểm gì khác nhau?
- Git: Git là một hệ thống kiểm soát phiên bản phân tán để theo dõi các thay đổi mã nguồn trong quá trình phát triển phần mềm.
- GitHub: GitHub là một dịch vụ lưu trữ kho lưu trữ Git dựa trên web, cung cấp tất cả chức năng kiểm soát bản sửa đổi phân tán và quản lý mã nguồn (SCM) của Git cũng như thêm các tính năng riêng của nó.
| Git | Github |
| Là một hệ thống kiểm soát phiên bản để quản lý lịch sử mã nguồn | Là một dịch vụ lưu trữ cho kho lưu trữ Git |
| Là một công cụ dòng lệnh | Là một giao diện UI |
| Được cài đặt cục bộ trên hệ thống | Được lưu trữ trên web |
| Được bảo trì bởi cộng đồng | Hiện đang được sở hữu và phát triển bởi Microsoft, nhưng cộng đồng vẫn đóng góp rất lớn |
| Tập trung vào kiểm soát phiên bản và chia sẻ code | Tập trung vào lưu trữ code và truy xuất từ xa |
| Không có tính năng quản lý người dùng | Có tính năng quản lý người dùng tích hợp |
| Cung cấp một giao diện Desktop có tên là Git Gui | Cung cấp một giao diện Desktop có tên là GitHub Desktop |
| Cạnh tranh với CVS, Subversion, Mercurial,… | Cạnh tranh với GitLab, Bit Bucket, AWS Codecommit, Azure DevOps Server,… |
Sự khác biệt giữa MVC (Model View Controller) và MVP (Model View Presenter) là gì?
- Mô hình MVC gợi ý chia code thành 3 thành phần. Trong khi tạo lớp/tệp của ứng dụng, lập trình viên phải phân loại thành một trong ba lớp gồm: Model – Thành phần này lưu trữ dữ liệu ứng dụng, View – Lớp UI, Controller – Thiết lập mối quan hệ giữa View và Model.
- Mô hình MVP khắc phục được những thách thức của MVC và cung cấp cấu trúc code dự án. MVP gồm ba thành phần: Model – Lớp lưu trữ dữ liệu, View – Lớp UI và Presenter – Lấy dữ liệu từ mô hình và áp dụng logic UI để quyết định nội dung hiển thị.
| MVC | MVP |
| Một trong những kiến trúc phần mềm lâu đời nhất | Được phát triển như là phiên bản thứ hai của MVC |
| UI (View) và cơ chế truy cập dữ liệu (Model) được kết hợp chặt chẽ | Giải quyết vấn đề có View phụ thuộc bằng cách sử dụng Presenter làm kênh giao tiếp giữa Model và View |
| – Controller và View tồn tại với mối quan hệ một – nhiều
– Một Controller có thể chọn một View khác nhau dựa trên thao tác cần thiết |
Mối quan hệ 1 – 1 tồn tại giữa Presenter và View vì mỗi lớp Presenter quản lý một View tại một thời điểm |
| View không có kiến thức về Controller | View có tham chiếu đến Presenter |
| Khó thực hiện thay đổi và sửa đổi các tính năng của ứng dụng vì các lớp code được liên kết chặt chẽ | Các lớp code được liên kết lỏng lẻo nên dễ thực hiện sửa đổi/thay đổi trong mã ứng dụng |
| Đầu vào của người dùng được xử lý bởi Controller | Chế độ View là điểm vào của ứng dụng |
| Chỉ lý tưởng cho các dự án quy mô nhỏ | Lý tưởng cho các ứng dụng đơn giản và phức tạp |
| Hỗ trợ Unit Testing nếu controller được thiết kế tốt | Dễ thực hiện Unit Testing nhưng liên kết chặt chẽ giữa View và Presenter có thể gây ra đôi chút khó khăn |
| Ít phụ thuộc vào API Android | Phụ thuộc nhiều vào API Android |
| Không tuân theo nguyên tắc trách nhiệm đơn lẻ và theo mô-đun | Tuân theo nguyên tắc trách nhiệm đơn lẻ và theo mô-đun |
Câu hỏi phỏng vấn Fullstack Developer với Senior Fullstack Developer
Làm thế nào để kiểm soát session state trong load balancer?
Trong một kịch bản ứng dụng load balancer, vấn đề chính với session state là nếu hệ thống pbackend đang xử lý dữ liệu phiên trong bộ nhớ, thì các yêu cầu tiếp theo từ cùng một máy khách cần phải đến cùng một máy chủ, nếu không dữ liệu phiên sẽ bị phân mảnh và vô dụng.
Có hai cách chính để giải quyết vấn đề này:
- Phiên cố định (Sticky sessions): Cho phép định cấu hình load balancer để chuyển hướng các yêu cầu từ cùng một máy khách vào cùng một máy chủ mọi lúc.
- Lưu trữ phiên tập trung (Centralized session store): Giải pháp này liên quan đến việc đưa dữ liệu phiên ra khỏi các backend vào một kho dữ liệu tập trung mà tất cả các bản sao có thể truy cập. Điều này giúp bộ load balancer hoạt động dễ dàng hơn, nhưng đòi hỏi logic bổ sung và nhiều “bộ phận chuyển động” hơn.
Sự khác biệt giữa trình lặp Fail-Fast và Fail-Safe là gì?
| Fail-Fast | Fail-Safe |
| Dừng lặp lại và đưa ra ngoại lệ nếu cấu trúc dữ liệu cơ bản bị thay đổi trong quá trình lặp lại | Vẫn tiếp tục xử lý ngay cả khi cấu trúc dữ liệu cơ bản bị thay đổi trong quá trình lặp |
| Một đối tượng được sao chép không được tạo ra trong quá trình lặp lại | Một bản sao hoặc đối tượng sao chép được tạo ra |
| Không cho phép bất kỳ sửa đổi nào trong quá trình lặp lại | Cho phép sửa đổi trong quá trình lặp lại |
| Nhanh hơn Fail Safe Iterator | Chậm hơn Fail Fast |
Deadlock trong Java là gì và làm thế nào để tránh nó xảy ra?
Deadlock là tình huống trong Java khi hai hoặc nhiều luồng đang cố gắng truy cập cùng một đối tượng hoặc khi chúng cố gắng truy cập các tài nguyên khác nhau theo một thứ tự nhất định. Tình huống này chỉ xảy ra trong trường hợp đa luồng. Có thể tránh deadlock bằng các cách sau:
- Tránh khóa lồng nhau (nested locks): Tránh cấp khóa cho nhiều luồng nếu chúng ta đã cấp cho một luồng.
- Sử dụng thời gian chờ khóa (lock timeouts): Chúng ta có thể chỉ định thời gian cho một luồng để ngăn luồng đó phải chờ khóa vô thời hạn.
- Tránh khóa không cần thiết: Sử dụng khóa không cần thiết có thể dẫn đến bế tắc và chúng ta nên tránh tình trạng này.
- Sử dụng khóa leo thang (lock escalation): Khóa leo thang (lock escalation) giúp chuyển đổi nhiều khóa thành ít khóa hơn, giảm nguy cơ xảy ra bế tắc.
Hãy nêu một số kỹ thuật để cải thiện performance của một ứng dụng web
Hiệu suất của các ứng dụng web phụ thuộc vào nhiều yếu tố. Có rất nhiều cách và kỹ thuật có thể sử dụng để làm trang web hoạt động nhanh hơn. Dưới đây là một số kỹ thuật giúp cải thiện hiệu suất:
- Sử dụng bộ nhớ đệm & mạng phân phối nội dung
- Giảm thiểu các yêu cầu HTTP
- Hạn chế chuyển hướng
- Bật nén (compression)
- Tối ưu hoá dữ liệu
- Tối ưu hóa HTML, CSS and JavaScript
Bạn sẽ sử dụng chiến lược nào để quản lý kết nối cơ sở dữ liệu trong tình huống tải cao (high-load)?
Trong tình huống tải cao (high-load), có thể áp dụng các cách sau để cải thiện hiệu suất của kết nối cơ sở dữ liệu:
- Sử dụng nhóm kết nối để tái sử dụng các kết nối giúp giảm thời gian thiết lập kết nối mới.
- Cân bằng tải lưu lượng cơ sở dữ liệu (các truy vấn) giữa một nhóm cơ sở dữ liệu sẽ giúp phân phối tải.
- Ngay cả việc tối ưu hóa các truy vấn cũng có thể giảm thời gian bạn sử dụng mỗi kết nối, giúp tối ưu hóa việc sử dụng tài nguyên và giảm thiểu thời gian dành cho mỗi kết nối đang hoạt động.
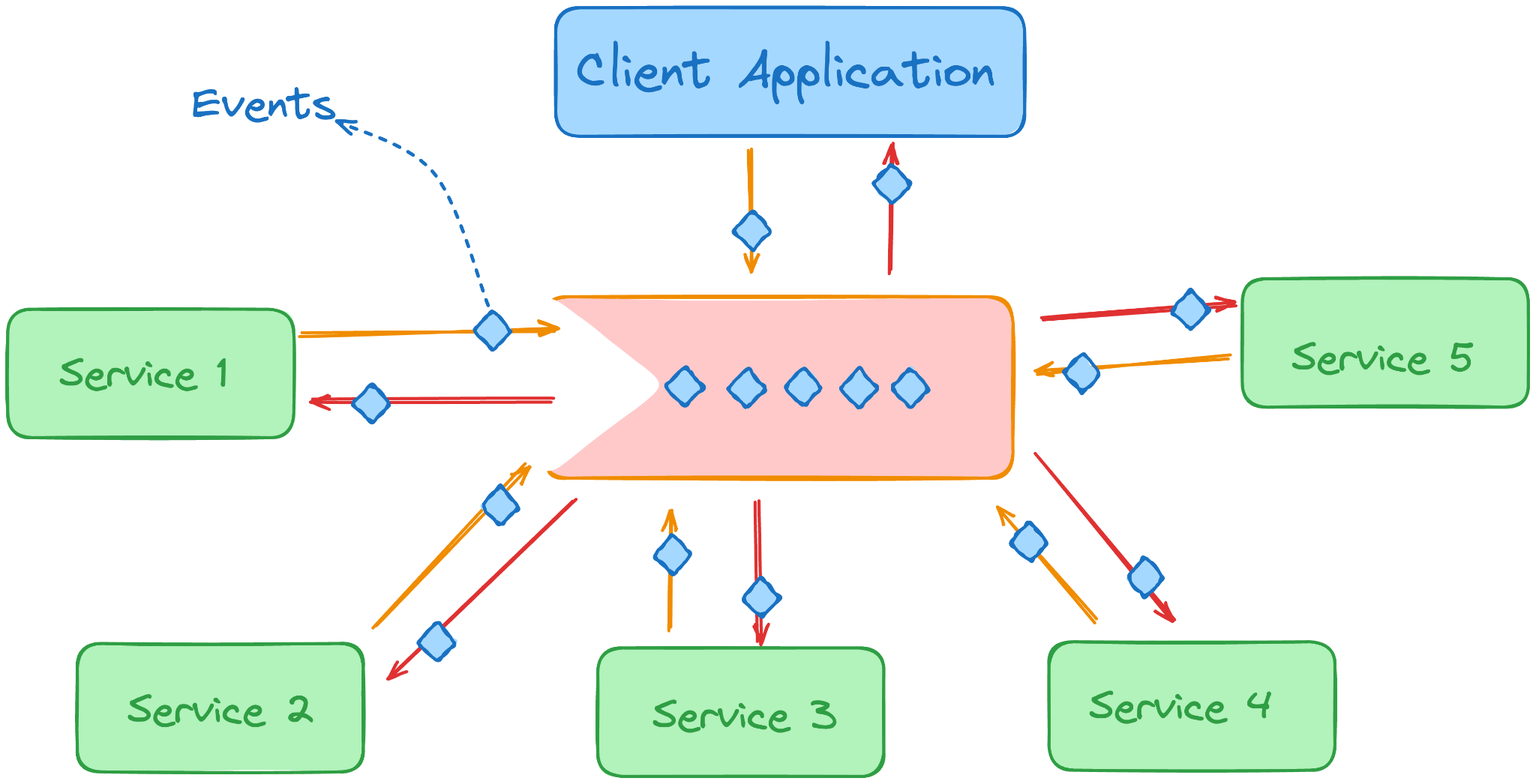
Hãy giải thích cách sử dụng và lợi ích của hàng đợi tin nhắn trong hệ thống phân tán (distributed system)
Hàng đợi tin nhắn trong hệ thống phân tán có thể hoạt động như thành phần cốt lõi của kiến trúc phản ứng (reactive architecture). Mỗi dịch vụ có thể kích hoạt và lắng nghe các sự kiện đến từ hàng đợi.
Theo cách đó, khi các sự kiện đến, các dịch vụ đó có thể phản ứng với chúng mà không cần phải chủ động thăm dò các dịch vụ khác để phản hồi.
Làm thế nào để bảo vệ server khỏi cuộc tấn công từ SQL injection?
SQL injection có thể phá hủy cơ sở dữ liệu bằng cách thêm mã độc hoặc hack cơ sở dữ liệu bằng cách thêm mã vào các câu query. Điều này xảy ra vì có rất ít sự tách biệt giữa mã chương trình và dữ liệu đầu vào của người dùng. SQL injection là một loại tấn công phổ biến vào cơ sở dữ liệu.
Có thể ngăn chặn tấn công bằng cách sử dụng các câu lệnh chuẩn bị (Prepared statements) và các tham số.
Ví dụ Java với JDBC:
PreparedStatement stmt = conn.prepareStatement("SELECT * FROM users WHERE username = ?"); stmt.setString(1, username); ResultSet rs = stmt.executeQuery(); 1
- Có các thủ tục được lưu trữ và xác định trước
- Có quy trình xác thực cho dữ liệu đầu vào, theo đó bạn có thể đưa dữ liệu đầu vào vào danh sách đen hoặc danh sách trắng
- Sử dụng nguyên tắc đặc quyền tối thiểu, tức là không cung cấp quyền truy cập loại quản trị viên cao cấp vào máy chủ cơ sở dữ liệu công khai. Do đó, ngay cả khi tin tặc có thể hack vào ứng dụng, cũng không làm ảnh hưởng đến tính toàn vẹn của cơ sở dữ liệu vì chúng sẽ không đủ quyền để thực thi.
Bạn sẽ thiết lập quy trình tích hợp liên tục/triển khai liên tục (CI/CD) cho các dịch vụ backend như thế nào?
Có nhiều cân nhắc khi thiết lập quy trình tích hợp liên tục/triển khai liên tục (CI/CD) cho các dịch vụ backend:
- Sử dụng GIT làm trình kích hoạt cho toàn bộ quy trình. Các đường ống (pipelines) xây dựng cho các dịch vụ backend sẽ được thực thi khi bạn đẩy code vào một nhánh cụ thể.
- Chọn đúng nền tảng CI/CD cho nhu cầu của bạn như GitHub Actions, GitLab CI/CD, CircleCI,…
- Đảm bảo các bài unit testing tự động được thực thi bên trong các đường ống
- Việc triển khai tự động chỉ nên diễn ra nếu tất cả bài kiểm tra được thực thi thành công. Nếu không, đường ống sẽ bị lỗi, ngăn không cho mã bị hỏng tiếp cận bất kỳ môi trường nào.
- Sử dụng kho lưu trữ hiện vật như JFrog Artifactory hoặc Nexus Repository để lưu trữ các dịch vụ đã xây dựng thành công.
- Cân nhắc thiết lập chiến lược khôi phục trong trường hợp có sự cố xảy ra và phiên bản triển khai cuối cùng của dịch vụ bị hỏng.
Bạn sẽ làm gì để xử lý các quy trình chạy lâu (long-running processes) trong các yêu cầu web?
Đối với các yêu cầu web kích hoạt quy trình chạy lâu (long-running processes), tùy chọn tốt nhất là triển khai kiến trúc phản ứng (reactive architecture). Điều này có nghĩa là khi một dịch vụ nhận được yêu cầu, nó sẽ chuyển đổi yêu cầu đó thành một thông báo bên trong hàng đợi thông báo và quy trình chạy lâu sẽ nhận yêu cầu đó bất cứ khi nào nó sẵn sàng thực hiện.
Trong khi đó, máy khách gửi yêu cầu này sẽ nhận được phản hồi ngay lập tức xác nhận rằng yêu cầu đang được xử lý. Bản thân máy khách cũng có thể được kết nối với hàng đợi thông báo (hoặc thông qua proxy) và chờ sự kiện “sẵn sàng” với tải trọng của nó bên trong.
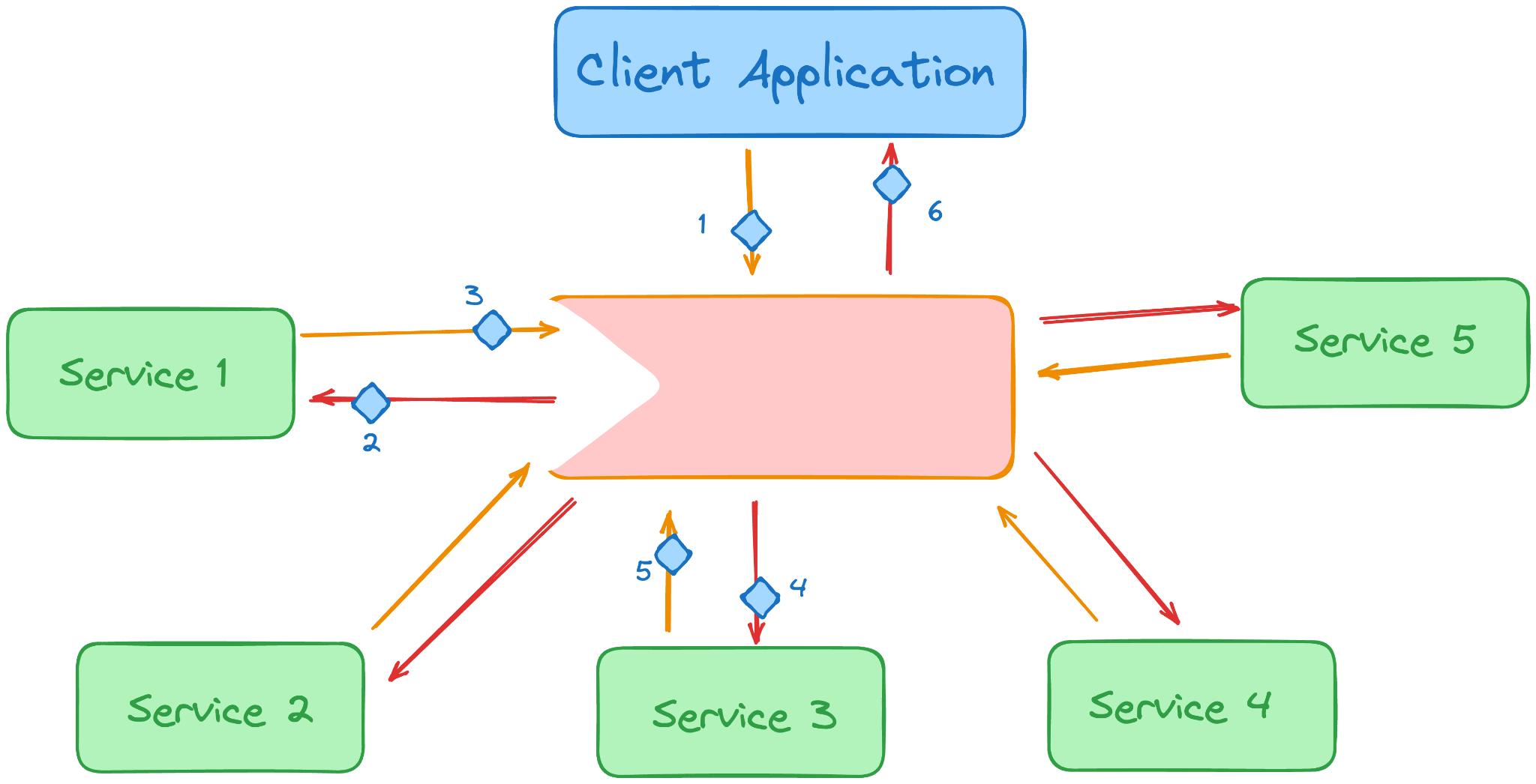
Bạn đã quản lý các phụ thuộc API trong các hệ thống backend như thế nào?
Cách tuyệt vời để xử lý các phụ thuộc API trong các hệ thống backend là tận dụng phiên bản API. Thông qua thực hành đơn giản này, bạn có thể đảm bảo rằng hệ thống hực sự đang sử dụng đúng API, ngay cả khi có nhiều phiên bản của API đó.
Điều này cũng cho phép có nhiều hệ thống backend sử dụng các phiên bản khác nhau của cùng một API mà không có bất kỳ rủi ro nào về sự nhất quán hoặc các bản cập nhật làm hỏng hệ thống.
Bạn sẽ thiết kế backend để hỗ trợ đồng bộ hóa dữ liệu theo thời gian thực trên nhiều thiết bị như thế nào?
Nếu muốn hỗ trợ đồng bộ hóa dữ liệu theo thời gian thực, cần phải tìm cách tạo kênh giao tiếp ổn định và hiệu quả giữa các thiết bị, đồng thời tìm cách giải quyết xung đột đồng bộ dữ liệu tiềm ẩn khi nhiều thiết bị đang cố gắng thay đổi cùng một bản ghi. Vì vậy, đối với các kênh giao tiếp, có thể sử dụng một trong các phương pháp sau:
- Kênh song hướng dựa trên socket cho phép trao đổi dữ liệu theo thời gian thực.
- Sử dụng mô hình pub/sub để phân phối dữ liệu hiệu quả giữa nhiều thiết bị.
- Sử dụng các thuật toán như chuyển đổi hoạt động (OT) hoặc kiểu dữ liệu sao chép không xung đột (CRDT).
Tổng kết câu hỏi phỏng vấn Fullstack Developer
Với 35+ câu hỏi phỏng vấn Fullstack Developer từ cơ bản đến nâng cao, từ lý thuyết đến thực hành, xử lý tình huống bên trên, ITviec mong rằng bạn sẽ có một buổi thể hiện thật tốt với nhà tuyển dụng.
