
Sự ra đời của Spring Data JPA đã thực sự thay đổi cách lập trình viên tiếp cận tầng dữ liệu. Spring Data JPA là một module của Spring Data framework, được xây dựng để đơn giản hóa tầng truy cập dữ liệu và giảm thiểu mã boilerplate, giúp tăng năng suất và giảm thiểu lỗi.
Đọc bài viết này để được giải đáp về:
- Vai trò của Spring Data JPA là gì? Có gì khác JPA, Hibernate
- Cách thiết lập và cài đặt Spring Data JPA
- Các thành phần chính của Spring Data JPA
- Cách khai thác các phương thức truy vấn trong Spring Data JPA
- Các kỹ thuật nâng cao với Spring Data JPA
- Các cách tối ưu hiệu năng khi làm việc với Spring Data JPA
- Cách khắc phục các lỗi thường gặp với Spring Data JPA
Spring Data JPA là gì?
Spring Data JPA là một module thuộc dự án Spring Data, được thiết kế để đơn giản hóa việc truy cập dữ liệu trong các ứng dụng Spring sử dụng JPA (Java Persistence API).
Vị trí của Spring Data JPA là nằm giữa tầng Business Logic của ứng dụng và tầng Persistence (cụ thể là Implementation của JPA). Nó cung cấp một mô hình lập trình dựa trên Repository (kho chứa), cho phép lập trình viên định nghĩa các interface truy vấn dữ liệu mà không cần viết mã triển khai. Spring Data JPA sẽ tự động tạo ra các cài đặt cần thiết lúc runtime.
Về cơ bản, nó không phải là một trình triển khai JPA (như Hibernate) mà là một lớp trừu tượng (abstraction layer) nằm phía trên JPA Provider. Mục tiêu chính của Spring Data JPA là giảm thiểu đáng kể mã boilerplate (mã lặp đi lặp lại) cần thiết để thực hiện các thao tác truy vấn dữ liệu, đặc biệt là các thao tác CRUD (Create, Read, Update, Delete).
Phân biệt vai trò của JPA, Hibernate và Spring Data JPA
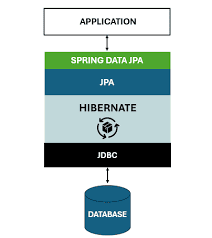
Vị trí của 3 thành phần này trong cấu trúc của 1 ứng dụng
JPA là một bộ tiêu chuẩn kỹ thuật (specification) của Java, định nghĩa một tập hợp các API, annotation và quy tắc để quản lý dữ liệu quan hệ trong các ứng dụng Java. Nó chỉ là một bản thiết kế, đưa ra các khái niệm như EntityManager, Entity, @Id, @Table, và ngôn ngữ truy vấn JPQL (Java Persistence Query Language).
2. Hibernate
Hibernate là một trình triển khai (implementation) cụ thể và phổ biến nhất của JPA. Nó hiện thực hóa các tiêu chuẩn mà JPA đã đề ra. Hibernate cung cấp EntityManager thực tế, xử lý việc ánh xạ đối tượng Java (Object) sang các bản ghi trong cơ sở dữ liệu (Relational) – gọi là ORM (Object-Relational Mapping). Ngoài JPA, Hibernate còn cung cấp nhiều tính năng mở rộng của riêng nó.
3. Spring Data JPA
Spring Data JPA là một lớp trừu tượng nằm trên cùng, giúp việc tương tác với dữ liệu trở nên dễ dàng hơn rất nhiều. Thay vì phải tự tay viết các câu lệnh truy vấn phức tạp bằng JPQL hoặc Criteria API, bạn chỉ cần định nghĩa các interface Repository. Spring Data JPA sẽ tự động sinh ra các phương thức CRUD cơ bản (save(), findById(), findAll(), delete()) và cả các truy vấn phức tạp hơn dựa trên tên phương thức (Query Methods).
Tóm lại, Spring Data JPA đơn giản hóa việc sử dụng tập hợp các quy tắc JPA (Java Persistence API) bằng cách cung cấp một lớp trừu tượng cấp cao hơn, trong khi Hibernate là một trong những công cụ hiện thực hóa các quy tắc của JPA đó.
Cách thiết lập và cài đặt Spring Data JPA
Để bắt đầu với Spring Data JPA, bạn cần thêm các dependency cần thiết vào project và cấu hình thông tin kết nối đến cơ sở dữ liệu.
Cài đặt Dependencies
Phần này hướng dẫn cách thêm các thư viện cần thiết vào dự án của bạn bằng Maven hoặc Gradle.
Trước khi bắt đầu, hãy đảm bảo bạn đã có:
- JDK: Java Development Kit, phiên bản 8 trở lên (khuyến nghị 11 hoặc 17).
- Maven/Gradle: Công cụ quản lý dependency và build dự án.
- IDE: Môi trường phát triển tích hợp như IntelliJ IDEA, Eclipse, hoặc Visual Studio Code.
Bạn cần thêm hai loại dependency chính: starter của Spring Data JPA và driver của cơ sở dữ liệu bạn muốn sử dụng.
- Spring Boot Starter Data JPA: Đây là dependency “tất cả trong một”, nó đã bao gồm:
- Spring Data JPA: Lõi của thư viện.
- Spring ORM: Hỗ trợ tích hợp ORM.
- Hibernate: JPA Provider mặc định.
- JDBC: API kết nối CSDL tầng thấp.
- Database Driver: Thư viện này giúp ứng dụng Java có thể “nói chuyện” được với một loại cơ sở dữ liệu cụ thể (ví dụ: PostgreSQL, MySQL).
- Spring Data JPA: Lõi của thư viện.
- Spring ORM: Hỗ trợ tích hợp ORM.
- JDBC: API kết nối CSDL tầng thấp.
- Database Driver: Thư viện này giúp ứng dụng Java có thể “nói chuyện” được với một loại cơ sở dữ liệu cụ thể (ví dụ: PostgreSQL, MySQL).
Dưới đây là cách khai báo trong Maven (pom.xml) và Gradle (build.gradle).
Đối với Maven (pom.xml)
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>Đối với Gradle (build.gradle)
dependencies {
// 1. Spring Data JPA Starter
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
// 2. Chọn MỘT trong các Database Driver sau
// H2 Database (In-memory, tốt cho testing)
runtimeOnly 'com.h2database:h2'
// PostgreSQL Driver
runtimeOnly 'org.postgresql:postgresql'
// MySQL Driver
runtimeOnly 'com.mysql:mysql-connector-j'
}Cấu hình datasource
Sau khi đã có dependencies, bạn cần khai báo thông tin để Spring Boot có thể kết nối đến cơ sở dữ liệu. Cấu hình này thường được đặt trong file src/main/resources/application.properties hoặc application.yml.
Dưới đây là các ví dụ cấu hình cho từng loại CSDL.
Sử dụng application.properties (cú pháp key=value)
# Cấu hình cho PostgreSQL
spring.datasource.url=jdbc:postgresql://localhost:5432/ten_database
spring.datasource.username=your_username
spring.datasource.password=your_password
# Cấu hình cho MySQL
# spring.datasource.url=jdbc:mysql://localhost:3306/ten_database
# spring.datasource.username=your_username
# spring.datasource.password=your_password
# Cấu hình cho H2 In-Memory Database (không cần username/password nếu dùng mặc định)
# spring.datasource.url=jdbc:h2:mem:testdb
# spring.datasource.driverClassName=org.h2.Driver
# spring.jpa.database-platform=org.hibernate.dialect.H2Dialect
# Cấu hình quan trọng của JPA Hibernate
spring.jpa.hibernate.ddl-auto=update
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.format_sql=trueSử dụng application.yml (cú pháp YAML)
spring:
datasource:
# Cấu hình cho PostgreSQL
url: jdbc:postgresql://localhost:5432/ten_database
username: your_username
password: your_password
# Cấu hình cho MySQL
# url: jdbc:mysql://localhost:3306/ten_database
# username: your_username
# password: your_password
# Cấu hình cho H2 In-Memory Database
# url: jdbc:h2:mem:testdb
# driverClassName: org.h2.Driver
jpa:
hibernate:
ddl-auto: update # Cấu hình quan trọng của JPA Hibernate
show-sql: true
properties:
hibernate:
format_sql: true
# database-platform: org.hibernate.dialect.H2Dialect # Cho H2Giải thích các thuộc tính thiết yếu:
spring.datasource.url: Chuỗi kết nối JDBC đến cơ sở dữ liệu. Cú pháp sẽ khác nhau tùy loại CSDL.spring.datasource.username: Tên người dùng để đăng nhập vào CSDL.spring.datasource.password: Mật khẩu của người dùng.spring.jpa.hibernate.ddl-auto: Đây là một thuộc tính cực kỳ quan trọng, nó ra lệnh cho Hibernate phải làm gì với schema (cấu trúc bảng) của cơ sở dữ liệu khi ứng dụng khởi động.
Các thành phần chính của Spring Data JPA
Sau khi đã tìm hiểu sơ lược cũng như cách thiết lập và cài đặt môi trường phát triển, chúng ta sẽ quay lại tìm hiểu về các thành phần chính trong Spring Data JPA:
Entity – Ánh xạ Object-Relational
Một Entity là một lớp Java thông thường (POJO – Plain Old Java Object) được “đánh dấu” để đại diện cho một bảng trong cơ sở dữ liệu. Quá trình ánh xạ này (Object-Relational Mapping – ORM) được thực hiện thông qua các annotation dưới đây:
@Entity: Annotation quan trọng nhất, báo cho JPA biết rằng lớp này là một thực thể cần được quản lý và ánh xạ xuống một bảng CSDL.
@Table(name = "ten_bang"): Tùy chọn, dùng để chỉ định tên bảng trong CSDL. Nếu bỏ qua, JPA sẽ tự lấy tên của lớp (thường là ở dạng snake_case).
@Id: Đánh dấu một trường là khóa chính (primary key) của bảng. Mỗi Entity bắt buộc phải có một khóa chính.
@GeneratedValue: Cấu hình cách mà khóa chính được sinh tự động. Có nhiều chiến lược (strategy) khác nhau:
GenerationType.IDENTITY: Phù hợp với các CSDL hỗ trợ cột tự tăng (auto-increment) như MySQL, PostgreSQL.GenerationType.SEQUENCE: Sử dụng một sequence trong CSDL để sinh khóa, phổ biến với Oracle, PostgreSQL.GenerationType.AUTO: Mặc định, JPA Provider (Hibernate) sẽ tự chọn chiến lược phù hợp nhất.
@Column(name = "ten_cot"): Tùy chỉnh ánh xạ cho một trường với một cột. Bạn có thể định nghĩa tên cột, ràng buộc nullable, unique, length, v.v.
Ví dụ: Lớp User Entity
import jakarta.persistence.*; // Hoặc javax.persistence.* cho Spring Boot 2.x
import java.time.LocalDate;
@Entity
@Table(name = "users") // Ánh xạ tới bảng tên là "users"
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY) // Khóa chính tự tăng
private Long id;
@Column(name = "username", nullable = false, unique = true, length = 50)
private String username;
@Column(name = "email", nullable = false, unique = true)
private String email;
@Column(nullable = false) // Tên cột sẽ tự động là "password"
private String password;
@Column(name = "birth_date")
private LocalDate birthDate;
// Constructors, Getters, Setters, toString()...
// (Bỏ qua để cho gọn)
}Repository
Repository Pattern là một mẫu thiết kế nhằm tạo ra một lớp trừu tượng giữa tầng business logic và tầng truy cập dữ liệu. Nó đóng vai trò như một “kho chứa” các đối tượng, giúp che giấu đi sự phức tạp của việc truy vấn CSDL.
Trong Spring Data JPA, bạn không cần phải viết lớp triển khai cho Repository. Thay vào đó, bạn chỉ cần định nghĩa một interface kế thừa từ JpaRepository.
JpaRepository<T, ID> Đây là một giao diện đặc biệt của Spring Data JPA cung cấp sẵn rất nhiều phương thức hữu ích:
- Các thao tác CRUD đầy đủ:
save(),findById(),findAll(),deleteById(),… - Các thao tác phân trang và sắp xếp.
- Các thao tác batch (xử lý theo lô):
saveAll(),deleteAllInBatch(),…
Bạn chỉ cần cung cấp 2 tham số:
T: Lớp Entity mà repository này sẽ quản lý (ví dụ:User).ID: Kiểu dữ liệu của khóa chính trong Entity đó (ví dụ:Long).
Ví dụ: UserRepository Interface
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
// Spring Data JPA sẽ tự động cung cấp các phương thức CRUD tại đây.
// Bạn không cần viết bất kỳ dòng code triển khai nào!
// Chúng ta sẽ tìm hiểu cách thêm các phương thức truy vấn tùy chỉnh ở phần sau.
}Chỉ với vài dòng code ngắn gọn như trên, bạn đã có một tầng DAO (Data Access Object) hoàn chỉnh cho User entity.
Các thao tác CRUD cơ bản
Bây giờ, hãy xem cách sử dụng UserRepository trong một lớp Service để thực hiện các thao tác cơ bản.
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Optional;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
/**
* CREATE / UPDATE: Tạo mới hoặc cập nhật người dùng.
* Phương thức save() đủ thông minh để biết khi nào nên INSERT, khi nào nên UPDATE.
* - Nếu đối tượng User có id = null -> INSERT.
* - Nếu đối tượng User có id đã tồn tại trong DB -> UPDATE.
*/
public User saveUser(User user) {
return userRepository.save(user);
}
/**
* READ: Tìm một người dùng theo ID.
* Trả về một Optional<User> để xử lý trường hợp không tìm thấy user,
* tránh lỗi NullPointerException.
*/
public Optional<User> findUserById(Long id) {
return userRepository.findById(id);
}
/**
* READ: Lấy tất cả người dùng.
*/
public List<User> findAllUsers() {
return userRepository.findAll();
}
/**
* DELETE: Xóa người dùng theo ID.
*/
public void deleteUserById(Long id) {
// Nên kiểm tra sự tồn tại trước khi xóa để xử lý lỗi tốt hơn
if (userRepository.existsById(id)) {
userRepository.deleteById(id);
} else {
// Ném ra một exception hoặc xử lý theo logic nghiệp vụ
throw new RuntimeException("User not found with id: " + id);
}
}
/**
* DELETE: Xóa người dùng bằng cách truyền vào đối tượng entity.
*/
public void deleteUser(User user) {
userRepository.delete(user);
}
}Sau đó chúng ta có thể sử dụng UserService như sau:
// Giả sử trong một lớp Controller hoặc một lớp khác...
// @Autowired private UserService userService;
// 1. Tạo người dùng mới
User newUser = new User();
newUser.setUsername("tien_tran");
newUser.setEmail("tien_tran@google.com");
newUser.setPassword("password123");
User savedUser = userService.saveUser(newUser);
System.out.println("User đã được lưu với ID: " + savedUser.getId());
// 2. Tìm người dùng theo ID
Optional<User> foundUser = userService.findUserById(1L);
foundUser.ifPresent(user -> System.out.println("Tìm thấy user: " + user.getUsername()));
// 3. Cập nhật người dùng
foundUser.ifPresent(user -> {
user.setEmail("gemini.updated@google.com");
userService.saveUser(user); // Dùng lại phương thức save()
System.out.println("Đã cập nhật email cho user: " + user.getUsername());
});
// 4. Lấy tất cả user
List<User> allUsers = userService.findAllUsers();
System.out.println("Danh sách tất cả user: " + allUsers);
// 5. Xóa user
userService.deleteUserById(1L);
System.out.println("Đã xóa user với ID 1.");Hướng dẫn khai thác các phương thức truy vấn trong Spring Data JPA
Query Derivation – Tạo truy vấn từ tên phương thức
Đây là tính năng nổi trội nhất của Spring Data JPA. Thay vì phải tự tay viết những câu lệnh truy vấn phức tạp, bạn chỉ cần đặt tên cho phương thức của mình theo một quy ước nhất định. Spring Data JPA sẽ tự động phân tích tên phương thức đó và dịch nó thành một câu lệnh truy vấn tương ứng để thực thi dưới cơ sở dữ liệu.
Cơ chế này hoạt động bằng cách nhận diện các thuộc tính trong đối tượng của bạn (ví dụ: email, name, age) và kết hợp chúng với các từ khóa đặc biệt.
Hãy tưởng tượng bạn đang ra lệnh bằng ngôn ngữ tự nhiên:
- Để tìm người dùng bằng email, bạn chỉ cần một phương thức tên là
findByEmail. - Muốn tìm người dùng đầu tiên có tên cho trước và sắp xếp theo ngày cập nhật mới nhất? Hãy đặt tên phương thức là
findFirstByNameOrderByLastModifiedDateDesc.
Một số từ khóa phổ biến bạn có thể dùng để ghép nối và xây dựng các “câu lệnh” ngay trên tên phương thức bao gồm:
- And, Or: Để kết hợp nhiều điều kiện, ví dụ như tìm theo
tên VÀ họ. - Between, LessThan, GreaterThan: Để thực hiện các phép so sánh với số hoặc ngày tháng, ví dụ như tìm sản phẩm có giá
NẰM GIỮA100 và 200. - Like, Containing: Để tìm kiếm một phần của chuỗi văn bản, ví dụ như tìm bài viết có tiêu đề
CHỨAtừ “Spring”. - In: Để tìm những đối tượng có thuộc tính nằm trong một danh sách cho trước.
- OrderBy: Để sắp xếp kết quả trả về theo một thuộc tính nào đó, ví dụ
SẮP XẾP THEOtên theo thứ tự tăng dần.
Bằng cách kết hợp các từ khóa này, bạn có thể tạo ra vô số các truy vấn khác nhau mà không cần viết một dòng lệnh SQL nào.
Truy vấn tường minh với @Query
Tất nhiên, không phải lúc nào việc đặt một cái tên dài ngoằng cho phương thức cũng là giải pháp hay, đặc biệt là với các logic phức tạp. Đây là lúc chú thích @Query phát huy tác dụng. Nó cho phép bạn tự định nghĩa câu lệnh truy vấn của riêng mình.
Có hai cách chính để viết truy vấn với @Query:
- Dùng JPQL (Java Persistence Query Language): Đây là cách được khuyến khích. Thay vì viết lệnh trên các bảng và cột của cơ sở dữ liệu, bạn sẽ viết lệnh truy vấn trên các đối tượng (Entity) và thuộc tính của chúng. Điều này giúp ứng dụng của bạn không bị phụ thuộc vào một loại cơ sở dữ liệu cụ thể nào. Bạn có thể dễ dàng truyền tham số vào câu lệnh một cách an toàn thông qua các tham số được đặt tên (named parameters).
- Dùng Native SQL: Đôi khi, bạn cần sử dụng một tính năng rất riêng biệt chỉ có ở một hệ quản trị cơ sở dữ liệu nhất định (ví dụ: PostgreSQL, Oracle). Native SQL cho phép bạn viết một câu lệnh SQL thuần và Spring Data JPA sẽ thực thi nó trực tiếp. Tuy nhiên, cần lưu ý rằng cách làm này sẽ làm mất đi tính linh hoạt của ứng dụng. Nếu sau này bạn muốn đổi sang một loại cơ sở dữ liệu khác, những câu lệnh Native SQL này có thể sẽ bị lỗi và bạn phải viết lại chúng.
Phân trang và sắp xếp (Paging & Sorting)
Khi ứng dụng của bạn có hàng ngàn, hàng triệu bản ghi, việc tải tất cả chúng lên trong một lần là điều không thể. Spring Data JPA cung cấp một giải pháp cực kỳ thanh lịch cho bài toán này thông qua hai khái niệm: Phân trang (Paging) và Sắp xếp (Sorting).
Bạn có thể thêm các tham số đặc biệt vào phương thức truy vấn của mình để yêu cầu Spring Data JPA tự động xử lý việc này.
- Tham số Sort cho phép bạn chỉ định cách sắp xếp kết quả (ví dụ: sắp xếp theo giá từ cao đến thấp).
- Tham số Pageable mạnh mẽ hơn, nó bao gồm cả thông tin sắp xếp và thông tin phân trang (bạn muốn lấy trang thứ mấy? và mỗi trang có bao nhiêu mục?).
Khi bạn sử dụng Pageable, kết quả trả về không phải là một danh sách đơn thuần. Thay vào đó, bạn sẽ nhận được một đối tượng Page đặc biệt. Đối tượng này rất hữu ích vì nó chứa:
- Nội dung của trang hiện tại: Danh sách các mục thuộc về trang bạn yêu cầu.
- Thông tin phân trang: Tổng số bản ghi, tổng số trang, trang hiện tại là trang thứ mấy, có phải trang đầu tiên hay trang cuối cùng không.
Với những thông tin này, việc xây dựng các chức năng như thanh điều hướng “Next”, “Previous”, “Go to page…” trên giao diện người dùng trở nên vô cùng đơn giản.
Các kỹ thuật nâng cao với Spring Data JPA
Khi đã nắm vững những kiến thức cơ bản, bạn có thể nâng tầm ứng dụng của mình bằng các kỹ thuật mạnh mẽ hơn. Những công cụ này giúp bạn giải quyết các bài toán phức tạp về hiệu năng, quản lý dữ liệu và xây dựng truy vấn động.
Quản lý quan hệ giữa các Entity
Trong thực tế, các đối tượng dữ liệu luôn có mối liên kết với nhau. Spring Data JPA cung cấp các công cụ để định nghĩa và quản lý những mối quan hệ này một cách hiệu quả.
- Ánh xạ các mối quan hệ: Bạn dùng các annotation như @OneToOne, @OneToMany, @ManyToOne, và @ManyToMany để mô tả cách các entity liên kết với nhau.
- Thuộc tính
cascadevàfetch type:- Cascade: Quyết định xem các hành động (lưu, xóa, cập nhật) có nên được “lan truyền” sang các entity liên quan hay không.
- Fetch Type: Quyết định khi nào dữ liệu liên quan sẽ được tải. LAZY (chỉ tải khi cần) là lựa chọn tốt cho hiệu năng, trong khi EAGER (tải ngay lập tức) có thể gây ra vấn đề N+1 Query.
Giải quyết vấn đề N+1 Query
Đây là một “cạm bẫy” hiệu năng kinh điển. Nó xảy ra khi bạn tải N entity, rồi lại phải thực hiện thêm N truy vấn nữa để lấy dữ liệu liên quan.
Cách giải quyết: Sử dụng @EntityGraph để chỉ thị cho JPA biết cần tải đồng thời các dữ liệu liên quan trong một câu truy vấn duy nhất.
Ví dụ: Giải quyết N+1 query khi lấy danh sách tác giả (Author) và các bài viết (Post) của họ.
// Trong entity Author
@Entity
public class Author {
@Id
private Long id;
private String name;
// Mặc định là LAZY fetching, có thể gây ra N+1 query
@OneToMany(mappedBy = "author")
private List<Post> posts;
// Getters and setters
}Để khắc phục, ta dùng @EntityGraph trong repository để báo JPA tải luôn danh sách posts.
// Trong AuthorRepository
public interface AuthorRepository extends JpaRepository<Author, Long> {
// Báo cho JPA rằng khi tìm kiếm Author, hãy tải đồng thời thuộc tính "posts".
@EntityGraph(attributePaths = { "posts" })
List<Author> findAll();
}Thao tác này sẽ gộp N+1 câu truy vấn thành một câu truy vấn duy nhất dùng JOIN, giúp cải thiện đáng kể hiệu năng.
Quản lý transactions (giao dịch)
Giao dịch đảm bảo rằng một chuỗi các thao tác với cơ sở dữ liệu diễn ra như một khối công việc duy nhất: hoặc tất cả cùng thành công, hoặc tất cả cùng thất bại.
- Vai trò của
@Transactional: Annotation này khai báo một phương thức sẽ được thực thi bên trong một giao dịch. Nếu có lỗi, toàn bộ các thay đổi sẽ được rollback (khôi phục lại trạng thái ban đầu). - Đặt
@Transactionalở đâu: Quy tắc phổ biến nhất là đặt tại tầng Service (Service Layer), vì một nghiệp vụ ở tầng này thường bao gồm nhiều thao tác với cơ sở dữ liệu.
Ví dụ: Một service đăng ký người dùng, bao gồm việc lưu người dùng và ghi log hành động.
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
@Autowired
private LogRepository logRepository;
// Toàn bộ phương thức này được bao bọc trong một giao dịch.
// Nếu saveLog thất bại, việc tạo user cũng sẽ được hủy bỏ.
@Transactional
public void registerUser(User user, String action) {
userRepository.save(user); // Thao tác 1
// Giả sử có lỗi xảy ra ở đây
if (action.equals("INVALID_ACTION")) {
throw new RuntimeException("Hành động không hợp lệ!");
}
logRepository.save(new Log(action)); // Thao tác 2
}
}Projections: Lấy dữ liệu tối giản
Projections là kỹ thuật cho phép bạn chỉ truy vấn và lấy về những cột dữ liệu cần thiết thay vì toàn bộ entity, giúp tối ưu hiệu năng.
Cách thực hiện phổ biến nhất: Dùng Interface-based Projections. Bạn tạo một interface chỉ chứa các phương thức getter cho những thuộc tính bạn muốn lấy.
Ví dụ: Lấy thông tin tóm tắt của sản phẩm (Product) thay vì tất cả các trường.
// Entity Product có nhiều trường
@Entity
public class Product {
@Id
private Long id;
private String name;
private double price;
private String description;
private LocalDateTime createdAt;
// ...
}
// Projection interface chỉ định các trường cần lấy
public interface ProductSummary {
String getName();
double getPrice();
}Sau đó, trong repository, bạn khai báo phương thức trả về kiểu Product Summary.
// Trong ProductRepository
public interface ProductRepository extends JpaRepository<Product, Long> {
// Spring Data JPA sẽ tự động tạo query chỉ SELECT 2 cột name và price
List<ProductSummary> findByCategory(String category);
}Xây dựng truy vấn động (Dynamic Queries)
Đây là bài toán thường gặp khi xây dựng các chức năng tìm kiếm phức tạp với nhiều bộ lọc tùy chọn.
Spring Data JPA cung cấp Specifications cho phép bạn định nghĩa các điều kiện truy vấn thành những khối logic nhỏ, độc lập và có thể tái sử dụng.
Ví dụ: Xây dựng truy vấn động để tìm sản phẩm theo tên và giá.
Đầu tiên, tạo một lớp chứa các “mảnh” truy vấn có thể tái sử dụng.
public class ProductSpecifications {
// Trả về một điều kiện "name LIKE %keyword%"
public static Specification<Product> nameContains(String keyword) {
return (root, query, criteriaBuilder) ->
criteriaBuilder.like(root.get("name"), "%" + keyword + "%");
}
// Trả về một điều kiện "price > minPrice"
public static Specification<Product> priceGreaterThan(double minPrice) {
return (root, query, criteriaBuilder) ->
criteriaBuilder.greaterThan(root.get("price"), minPrice);
}
}Sau đó, trong repository, hãy kế thừa JpaSpecificationExecutor và kết hợp các Specification lại.
// ProductRepository cần kế thừa JpaSpecificationExecutor
public interface ProductRepository extends JpaRepository<Product, Long>, JpaSpecificationExecutor<Product> {
}
// Trong tầng Service, bạn có thể kết hợp các điều kiện
@Service
public class ProductService {
@Autowired
private ProductRepository productRepository;
public List<Product> searchProducts(String nameKeyword, double minPrice) {
// Bắt đầu với một Specification rỗng
Specification<Product> spec = Specification.where(null);
if (nameKeyword != null) {
// Nối thêm điều kiện tên
spec = spec.and(ProductSpecifications.nameContains(nameKeyword));
}
if (minPrice > 0) {
// Nối thêm điều kiện giá
spec = spec.and(ProductSpecifications.priceGreaterThan(minPrice));
}
return productRepository.findAll(spec);
}
}Các cách tối ưu hiệu năng khi làm việc với Spring Data JPA
Viết code chạy đúng là một chuyện, nhưng viết code chạy nhanh và hiệu quả lại là một thử thách khác.
Tối ưu hóa trong JPA chủ yếu xoay quanh việc giảm số lần tương tác với cơ sở dữ liệu và giảm lượng dữ liệu truyền tải trong mỗi lần tương tác. Vì các thao tác với database thường là khâu chậm nhất trong ứng dụng, tối ưu chúng sẽ mang lại hiệu quả rõ rệt.
Dưới đây là các phương pháp và kinh nghiệm thực tế để tối ưu hóa hiệu năng khi làm việc với Spring Data JPA:
Sử dụng Caching Strategies
Caching lưu trữ dữ liệu thường xuyên truy cập vào bộ nhớ để không phải truy vấn lại từ database.
- First-Level Cache (L1 Cache): Đây là bộ đệm mặc định và tự động của Hibernate, gắn liền với một phiên làm việc (Session) hay một giao dịch (
@Transactional). Nếu bạn truy vấn cùng một đối tượng hai lần bên trong cùng một phương thức service, Hibernate sẽ chỉ đánh vào database ở lần đầu tiên, còn lần thứ hai nó sẽ lấy ngay từ bộ nhớ. Bạn không cần cấu hình gì cả, nhưng cần biết nó tồn tại. - Second-Level Cache (L2 Cache): Đây là bộ đệm được chia sẻ giữa nhiều giao dịch và người dùng khác nhau.
L2 Cache dùng cho các dữ liệu ít thay đổi nhưng được đọc rất thường xuyên (ví dụ: danh mục sản phẩm, danh sách quốc gia, cấu hình hệ thống). Việc cache chúng sẽ giảm tải đáng kể cho database.
L2 Cache giúp tối ưu các truy vấn đọc (SELECT) lặp đi lặp lại trên các bảng dữ liệu tĩnh.
Cách làm: L2 Cache không được bật mặc định. Bạn cần thêm một thư viện cache (như EhCache, Hazelcast) và kích hoạt nó.
Ví dụ cấu hình L2 Cache với EhCache:
Properties
# application.properties
# Kích hoạt L2 Cache
spring.jpa.properties.hibernate.cache.use_second_level_cache=true
# Chỉ định nhà cung cấp cache
spring.jpa.properties.hibernate.cache.region.factory_class=org.hibernate.cache.ehcache.EhCacheRegionFactorySau đó, bạn chỉ cần đánh dấu các Entity bạn muốn cache bằng annotation @Cacheable.
Xử lý hàng loạt (Batch Processing)
Khi bạn cần INSERT hoặc UPDATE hàng ngàn bản ghi, việc gửi từng câu lệnh SQL một sẽ tạo ra hàng ngàn lượt đi-về (round-trip) giữa ứng dụng và database, cực kỳ lãng phí thời gian.
Batch Processing giúp tối ưu hiệu năng cho các thao tác ghi dữ liệu số lượng lớn (INSERT, UPDATE, DELETE) bằng cách nhóm chúng lại và gửi đi trong một lần.
Cách làm: Bạn có thể bật tính năng JDBC batching của Hibernate trong file cấu hình.
Ví dụ cấu hình JDBC Batching:
Properties
# application.properties
# Bật tính năng batch update
spring.jpa.properties.hibernate.jdbc.batch_size=50
# Sắp xếp các câu lệnh SQL để tối ưu batch
spring.jpa.properties.hibernate.order_inserts=true
spring.jpa.properties.hibernate.order_updates=trueCác best practices khác
Đây là những kinh nghiệm được đúc kết để giúp code của bạn sạch sẽ, dễ bảo trì và hiệu quả hơn.
- Luôn ưu tiên FetchType.LAZY: Đối với các mối quan hệ tập hợp (
@OneToMany,@ManyToMany), hãy luôn dùngLAZY. Việc này giúp bạn tránh tải một lượng lớn dữ liệu không cần thiết. Khi nào thực sự cần, hãy chủ động lấy chúng bằng@EntityGraphhoặcJOIN FETCH. - Dùng Projections (DTO) cho các màn hình danh sách: Đừng bao giờ
SELECT *khi bạn chỉ cần hiển thị 2-3 cột. Projections giúp bạn tạo ra những câu lệnhSELECTgọn nhẹ, chỉ lấy đúng những gì cần thiết. - Giữ Repository đơn giản: Repository chỉ nên chứa các phương thức truy vấn dữ liệu. Toàn bộ logic nghiệp vụ, tính toán, hay kết hợp nhiều lời gọi repository nên được đặt ở tầng Service.
- Hiểu câu lệnh SQL được sinh ra: Bạn không thể tối ưu thứ mà bạn không thấy. Một thực hành cực kỳ quan trọng là luôn theo dõi các câu lệnh SQL mà JPA/Hibernate tạo ra trong quá trình phát triển.
Cách làm: Bật tính năng ghi log SQL trong fileapplication.properties.
Properties
# Hiển thị câu lệnh SQL ra console
spring.jpa.show-sql=true
# Định dạng lại câu lệnh SQL cho dễ đọc
spring.jpa.properties.hibernate.format_sql=trueViệc này giúp bạn ngay lập tức phát hiện các vấn đề như N+1 query hay các câu JOIN không hiệu quả.
Các lỗi thường gặp với Spring Data JPA và cách khắc phục
Sử dụng FetchType.EAGER không cần thiết
Vấn đề: Gây ra tình trạng “over-fetching” (tải thừa dữ liệu), làm chậm các truy vấn và có thể ẩn giấu vấn đề N+1.
Khắc phục: Quy tắc vàng là: “Mặc định dùng LAZY, khi nào cần thì chủ động lấy”. Chuyển tất cả các FetchType.EAGER sang LAZY và sử dụng @EntityGraph ở repository để định nghĩa các trường cần lấy một cách tường minh.
Vấn đề N+1 Query
Vấn đề: Hiệu năng ứng dụng sụt giảm nghiêm trọng khi làm việc với danh sách. Một truy vấn lấy danh sách kéo theo N truy vấn con.
Khắc phục: Dùng log SQL để phát hiện. Sử dụng JOIN FETCH trong các câu lệnh @Query hoặc dùng @EntityGraph trên phương thức repository để giải quyết.
Thao tác trên dữ liệu ngoài phương thức @Transactional
Vấn đề: Khi bạn lấy một entity từ database, sau đó kết thúc phương thức @Transactional (tức là session đã đóng), bạn sẽ không thể truy cập vào các thuộc tính LAZY của entity đó nữa. Nếu cố làm vậy, bạn sẽ gặp lỗi LazyInitializationException.
Khắc phục: Đảm bảo toàn bộ chu trình xử lý một nghiệp vụ — từ lúc đọc dữ liệu, sửa đổi, cho đến lúc truy cập các thuộc tính liên quan — đều nằm gọn bên trong một phương thức được đánh dấu @Transactional ở tầng Service.
Các câu hỏi thường gặp về Spring Data JPA
Nguyên nhân và cách khắc phục lỗi LazyInitializationException?
Lỗi này xảy ra khi bạn cố gắng truy cập vào một thuộc tính hoặc một danh sách liên quan được tải theo kiểu LAZY (tải lười) sau khi phiên làm việc (database session) đã bị đóng.
- Nguyên nhân: Phổ biến nhất là khi bạn lấy một entity trong một phương thức service, trả nó về cho tầng controller, rồi ở controller bạn mới cố gắng lấy danh sách các entity con của nó. Lúc này, transaction đã kết thúc, session đã đóng, và JPA không thể quay lại database để tải dữ liệu được nữa.
- Cách khắc phục dứt điểm: Đảm bảo toàn bộ logic nghiệp vụ, bao gồm cả việc truy cập vào các dữ liệu
LAZY, đều được thực hiện bên trong một phương thức được đánh dấu@Transactionalở tầng Service. Điều này giữ cho session luôn mở trong suốt quá trình xử lý, cho phép JPA tải dữ liệu khi cần.
Spring Data JPA có nhiều cách tạo truy vấn (tên phương thức, @Query, Specifications). Khi nào nên dùng cách nào?
Lựa chọn đúng công cụ sẽ giúp code của bạn dễ đọc và bảo trì hơn. Dưới đây là một số quy tắc đơn giản:
- Dùng Query Derivation (tạo truy vấn từ tên phương thức): Khi bạn cần những truy vấn đơn giản, tĩnh, không có logic phức tạp. Ví dụ:
findByEmail(String email)hayfindFirstByOrderByIdDesc(). - Dùng
@Queryvới JPQL: Khi truy vấn của bạn phức tạp hơn, cầnJOINnhiều bảng, có các hàm tính toán, hoặc khi tên phương thức theo quy ước trở nên quá dài và khó đọc. - Dùng Specifications (hoặc Querydsl): Khi bạn cần xây dựng các truy vấn động, tức là các điều kiện
WHEREđược thêm vào dựa trên đầu vào của người dùng (ví dụ: một form tìm kiếm có nhiều bộ lọc tùy chọn).
Nên dùng FetchType.EAGER hay FetchType.LAZY cho các mối quan hệ?
Quy tắc vàng là: Luôn ưu tiên dùng FetchType.LAZY, đặc biệt là cho các mối quan hệ tập hợp như @OneToMany và @ManyToMany.
EAGER có vẻ tiện lợi vì nó tải mọi thứ ngay lập tức, nhưng nó chính là nguyên nhân hàng đầu gây ra các vấn đề về hiệu năng, đặc biệt là N+1 query. Nó buộc ứng dụng phải tải một lượng lớn dữ liệu mà có thể bạn không bao giờ dùng đến.
Cách tiếp cận tốt nhất là hãy để mọi thứ là LAZY. Khi nào bạn thực sự cần dữ liệu liên quan cho một trường hợp sử dụng cụ thể, hãy chủ động yêu cầu JPA tải chúng bằng cách sử dụng @EntityGraph hoặc JOIN FETCH.
“Projection” là gì và tại sao tôi phải quan tâm đến nó?
Projection là một kỹ thuật cho phép bạn chỉ truy vấn và lấy về một tập hợp con các cột dữ liệu từ database, thay vì lấy toàn bộ tất cả các cột của một entity.
Bạn nên quan tâm đến nó vì một lý do duy nhất: Hiệu năng.
Hãy tưởng tượng entity User của bạn có 30 cột, nhưng trên màn hình danh sách, bạn chỉ cần hiển thị username và email. Việc sử dụng Projection sẽ tạo ra câu lệnh SELECT username, email FROM users… thay vì SELECT * FROM users…. Điều này giúp giảm đáng kể lượng dữ liệu truyền tải giữa ứng dụng và database, làm cho ứng dụng của bạn nhanh hơn và tốn ít bộ nhớ hơn.
Vấn đề “N+1 query” là gì? Nó có thực sự nghiêm trọng không?
Đây là một trong những “cạm bẫy” hiệu năng nguy hiểm nhất khi làm việc với ORM. Nó xảy ra khi bạn thực hiện 1 câu truy vấn để lấy danh sách các đối tượng cha, sau đó lại thực hiện thêm N câu truy vấn nữa để lấy dữ liệu liên quan cho từng đối tượng cha đó.
Nó cực kỳ nghiêm trọng. Một chức năng trông có vẻ đơn giản có thể âm thầm tạo ra hàng trăm, thậm chí hàng ngàn lời gọi đến database, làm ứng dụng của bạn chậm đi trông thấy.
Cách dễ nhất để phát hiện ra nó là bật tính năng ghi log SQL (spring.jpa.show-sql=true). Nếu bạn thấy trong console log xuất hiện một câu SELECT đầu tiên, theo sau là hàng loạt các câu SELECT giống hệt nhau được thực thi lặp đi lặp lại, thì đó chính là dấu hiệu của N+1 query.
Tổng kết
Spring Data JPA không chỉ là một công cụ giúp loại bỏ các đoạn code boilerplate nhàm chán. Qua những gì chúng ta đã tìm hiểu, từ sự kỳ diệu của việc tự sinh truy vấn từ tên phương thức, sức mạnh kiểm soát của @Query, cho đến các kỹ thuật tối ưu hiệu năng với Projections và Caching, có thể thấy đây là một framework cực kỳ toàn diện.
Hi vọng rằng bài viết này đã cung cấp cho bạn một lộ trình rõ ràng để khai thác sâu hơn sức mạnh của Spring Data JPA, giúp bạn xây dựng những ứng dụng không chỉ chạy đúng, mà còn chạy nhanh và hiệu quả.
