Java Collection Framework (JCF) là một kiến trúc nền tảng trong Java, cung cấp các lớp và giao diện được thiết kế sẵn để lưu trữ và thao tác hiệu quả trên các nhóm đối tượng. Điểm mạnh của JCF nằm ở việc giúp lập trình viên tiết kiệm thời gian và công sức: thay vì tự triển khai các cấu trúc dữ liệu, bạn có thể sử dụng những giải pháp đã được tối ưu hóa về hiệu năng, giúp ứng dụng chạy nhanh hơn, đồng thời giữ cho mã nguồn sạch, gọn và dễ tái sử dụng.
Trên thực tế, JCF được ứng dụng trong hầu hết các tác vụ, chẳng hạn như dùng List để quản lý giỏ hàng trên trang thương mại điện tử, dùng Map để lưu cache thông tin người dùng nhằm tăng tốc độ truy xuất, hay sử dụng Queue để xếp hàng các tác vụ cần xử lý theo thứ tự.
Đọc bài viết này để hiểu thêm về:
- Các interfaces cốt lõi của Framework
- Sơ đồ phân cấp của Java Collection Framework
- Các Lớp Implementations Phổ Biến Nhất
- Lớp tiện ích của collection
- Lời khuyên và thực hành với Java Collection Framework
- Các câu hỏi thường gặp
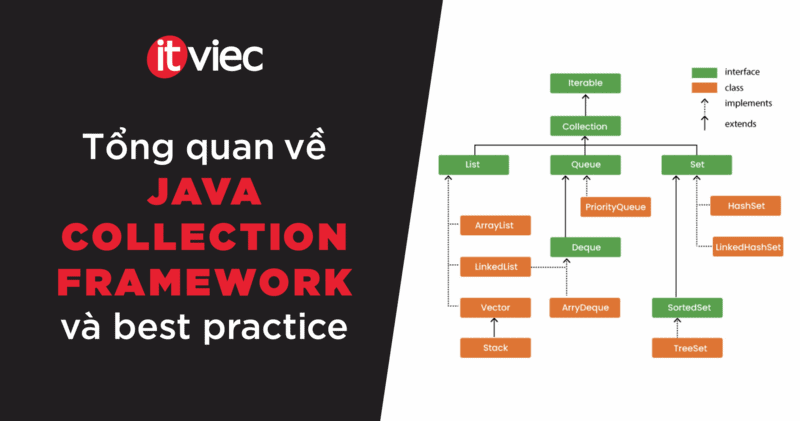
Sơ đồ phân cấp của Java Collection Framework

Sơ đồ phân cấp của Java Collection Framework (JCF) thể hiện hai nhóm thành phần chính:
- Hình chữ nhật xanh: Đây là các Interfaces. Chúng định nghĩa các hành vi, quy tắc và bộ phương thức mà một collection phải có, nhưng không cung cấp mã nguồn triển khai cụ thể. Chúng là “khuôn mẫu” cho các collection.
- Hình chữ nhật cam: Đây là các Classes (lớp triển khai cụ thể). Chúng là các lớp cung cấp mã nguồn hiện thực hóa các hành vi được định nghĩa trong các Interfaces. Khi lập trình, chúng ta sẽ khởi tạo đối tượng từ các class này.
Mũi tên trong sơ đồ biểu thị mối quan hệ:
- Mũi tên liền (Solid Arrow): Biểu thị sự kế thừa (extends). Ví dụ,
Collectionkế thừa từIterable, nghĩa làCollectioncó tất cả các tính năng củaIterablevà mở rộng thêm. - Mũi tên đứt (Dotted Arrow): Biểu thị sự triển khai (implements). Ví dụ,
ArrayListtriển khaiList, nghĩa làArrayListcung cấp mã nguồn cụ thể cho tất cả các phương thức được List interface yêu cầu.
Phân tích chi tiết theo cấp bậc
- Cấp gốc (The Root)
- Iterable: Đây là interface gốc của toàn bộ framework. Bất kỳ đối tượng nào triển khai
Iterableđều có khả năng cho phép chúng ta duyệt qua các phần tử của nó, điển hình nhất là bằng vòng lặpfor-each. - Collection: Interface này kế thừa từ
Iterablevà là “xương sống” cho hầu hết các cấu trúc dữ liệu. Nó định nghĩa các phương thức cơ bản nhất nhưadd(),remove(),size(),contains(), v.v.
- Các nhánh chính (The Main Branches)
Từ Collection, framework được chia thành ba nhánh chính, mỗi nhánh có một đặc tính riêng biệt: List, Set, và Queue.
- Nhánh
List(Danh sách có thứ tự): Lưu trữ một tập hợp các phần tử có thứ tự và cho phép trùng lặp. Bạn có thể truy cập phần tử qua chỉ số (index).
Các lớp triển khai phổ biến:ArrayList: Triển khai dựa trên mảng động (dynamic array). Rất nhanh cho việc truy cập ngẫu nhiên phần tử (dùngget(index)).LinkedList: Triển khai dựa trên danh sách liên kết đôi (doubly-linked list). Nhanh hơnArrayListtrong việc thêm/xóa phần tử ở giữa danh sách. Lưu ý rằngLinkedListcũng triển khai cảDeque.Vector: Một phiên bản cũ hơn và đồng bộ hóa (thread-safe) củaArrayList.Stacklà một lớp con của Vector, hoạt động theo cơ chế LIFO (Last-In, First-Out). Ngày nay,ArrayDequethường được ưu tiên sử dụng thay cho Stack.
- Nhánh Set (Tập hợp các phần tử duy nhất): Lưu trữ một tập hợp các phần tử duy nhất (không trùng lặp).
Các lớp triển khai phổ biến:
HashSet: Sử dụng bảng băm (hash table) để lưu trữ. Không đảm bảo thứ tự các phần tử. Cho hiệu năng rất cao (thời gian gần như không đổi) cho các thao tác cơ bản.LinkedHashSet: Kế thừa từ HashSet nhưng duy trì thứ tự chèn các phần tử.
Interface con SortedSet:
- Đây là một
Setmà các phần tử luôn được duy trì theo thứ tự được sắp xếp (thứ tự tự nhiên hoặc theo Comparator). TreeSet: Là lớp triển khai của SortedSet, sử dụng cấu trúc cây đỏ-đen (red-black tree) để đảm bảo các phần tử luôn được sắp xếp.
Các lớp triển khai phổ biến:
- Nhánh
Queue(Hàng đợi): Dùng để chứa các phần tử trước khi xử lý. Thường hoạt động theo nguyên tắc FIFO (First-In, First-Out) – vào trước ra trước.
Lớp triển khai: PriorityQueue: Một hàng đợi đặc biệt không tuân theo FIFO, thay vào đó, nó sắp xếp các phần tử dựa trên “độ ưu tiên” (thứ tự tự nhiên hoặc Comparator).
Interface con Deque (Double-Ended Queue):
- Đây là “hàng đợi hai đầu”, cho phép thêm/xóa phần tử ở cả đầu và cuối hàng đợi. Nhờ vậy, nó có thể được dùng như một
Queue(FIFO) hoặc mộtStack(LIFO). ArrayDeque: Là lớp triển khai củaDequedựa trên mảng động. Đây là lựa chọn được khuyến nghị cho cả hai nhu cầu về hàng đợi (queue) và ngăn xếp (stack) vì hiệu năng cao.LinkedList: Như đã đề cập,LinkedListcũng triển khai Deque.
Các Interfaces cốt lõi của Java Collection Framework
Trọng tâm của Java Collection Framework là một hệ thống các interface cốt lõi, định hình nên cấu trúc và hành vi của mọi collection. Việc hiểu rõ các interface này là chìa khóa để sử dụng framework một cách hiệu quả.
Iterable Interface
Nền tảng của toàn bộ hệ thống là Iterable, interface gốc của mọi collection. Nó cung cấp một phương thức duy nhất là iterator(), cho phép chúng ta duyệt qua tất cả các phần tử trong một collection, đây là chức năng cơ bản và thiết yếu nhất.
Collection Interface
Kế thừa từ Iterable, đây là interface gốc cho hầu hết các loại collection (ngoại trừ Map). Nó định nghĩa các hành vi và phương thức chung nhất mà một collection cần phải có, chẳng hạn như: thêm (add()), xóa (remove()), lấy kích thước (size()), xóa toàn bộ (clear()) và kiểm tra sự tồn tại của một phần tử (contains()).
Dựa trên Collection, chúng ta có các interface con với những đặc tính riêng biệt:
- List Interface: Đại diện cho một tập hợp có thứ tự và cho phép các phần tử trùng lặp. Điểm đặc trưng nhất của List là khả năng truy cập các phần tử thông qua chỉ số (index) giống như mảng, cho phép kiểm soát chính xác vị trí của từng phần tử.
- Set Interface: Ngược lại với List, Set đại diện cho một tập hợp không cho phép các phần tử trùng lặp. Hầu hết các triển khai của Set không đảm bảo thứ tự của các phần tử. Set rất hữu ích khi bạn chỉ quan tâm đến sự tồn tại của một phần tử mà không cần biết nó xuất hiện bao nhiêu lần.
- Queue Interface: Được thiết kế để xử lý các phần tử theo một thứ tự cụ thể. Queue hoạt động theo nguyên tắc First-In, First-Out (FIFO) – phần tử nào được thêm vào trước sẽ được xử lý trước. Nó thường được sử dụng trong các tác vụ lập lịch hoặc xử lý tuần tự.
Map Interface
Đứng tách biệt với hệ thống Collection là Map Interface. Thay vì lưu trữ các phần tử đơn lẻ, Map lưu trữ dữ liệu dưới dạng các cặp key-value. Mỗi key trong Map là duy nhất và được dùng để truy xuất value tương ứng. Đây là cấu trúc dữ liệu lý tưởng khi bạn cần tìm kiếm, cập nhật hoặc xóa một phần tử dựa trên một định danh duy nhất.
Các lớp triển khai (implementations) phổ biến trong Java collection framework
Nếu các interface là bản thiết kế, thì các lớp triển khai (implementations) chính là những công trình cụ thể được xây dựng từ bản thiết kế đó. Việc lựa chọn đúng lớp triển khai cho từng bài toán là yếu tố quyết định đến hiệu năng và sự hiệu quả của chương trình.
Triển khai của List Interface: ArrayList vs. LinkedList
| Tiêu chí | ArrayList | LinkedList |
| Cấu trúc Dữ liệu | Dựa trên mảng (array) có thể thay đổi kích thước. | Dựa trên danh sách liên kết kép (mỗi phần tử trỏ tới phần tử trước và sau nó) |
| Truy xuất phần tử (get) | Rất nhanh (O(1)). Truy cập trực tiếp qua chỉ số (index). | Chậm (O(n)). Phải duyệt từ đầu/cuối danh sách để tìm phần tử. |
| Thêm/Xóa phần tử | Chậm (O(n)). Phải dịch chuyển tất cả các phần tử phía sau. | Rất nhanh (O(1)). Chỉ cần thay đổi các con trỏ liên kết. |
| Sử dụng Bộ nhớ | Hiệu quả hơn, chỉ lưu trữ dữ liệu trong mảng. | Tốn nhiều bộ nhớ hơn do mỗi phần tử phải lưu thêm con trỏ next và prev. |
| Trường hợp sử dụng tốt nhất | Khi ứng dụng của bạn có nhu cầu đọc và truy cập dữ liệu thường xuyên hơn là chỉnh sửa. | Khi ứng dụng của bạn yêu cầu thêm và xóa phần tử liên tục, đặc biệt là ở đầu/cuối danh sách. |
Triển khai của Set Interface: HashSet, LinkedHashSet, và TreeSet
Khi bạn cần một tập hợp chỉ chứa các phần tử duy nhất, Set là lựa chọn hàng đầu.
HashSet
- Lưu trữ: Đây là lớp triển khai phổ biến và hiệu năng nhất. Nó sử dụng một
HashMapở bên dưới để lưu trữ các phần tử. - Đặc điểm: Nó không đảm bảo thứ tự của các phần tử. Khi bạn duyệt qua một
HashSet, thứ tự có thể thay đổi giữa các lần chạy. - Hiệu năng: Cung cấp hiệu năng tốt nhất cho các thao tác thêm (
add), xóa (remove), và kiểm tra (contains) với độ phức tạp trung bình là O(1).
LinkedHashSet
- Lưu trữ: Lớp này kế thừa
HashSetnhưng bổ sung thêm một danh sách liên kết để kết nối các phần tử. - Đặc điểm: Sự kết hợp này mang lại điều tốt nhất của cả hai: hiệu năng O(1) của
HashSetvà khả năng duy trì thứ tự các phần tử khi được thêm vào (insertion-order). - Khi nào nên dùng: Khi bạn cần sự duy nhất của
Setnhưng vẫn muốn duyệt qua các phần tử theo đúng thứ tự bạn đã thêm chúng.
TreeSet
- Lưu trữ:
TreeSetsử dụng cấu trúc cây đỏ-đen (Red-Black Tree) để lưu trữ dữ liệu. - Đặc điểm: Điểm đặc trưng nhất của
TreeSetlà nó luôn giữ cho các phần tử được sắp xếp. Các phần tử sẽ được sắp xếp theo thứ tự tự nhiên (ví dụ: số tăng dần, chữ cái theo alphabet) hoặc theo mộtComparatordo bạn định nghĩa. - Hiệu năng: Các thao tác cơ bản có độ phức tạp là O(log n), chậm hơn HashSet nhưng đổi lại bạn có một tập hợp luôn được sắp xếp.
Triển khai của Map Interface: HashMap, LinkedHashMap, và TreeMap
Map được dùng để lưu trữ dữ liệu dưới dạng các cặp khóa-giá trị (key-value).
HashMap
- Lưu trữ: Đây là lớp triển khai tiêu chuẩn và được sử dụng nhiều nhất cho
Map. Nó được xây dựng dựa trên một bảng băm. - Đặc điểm:
HashMapkhông đảm bảo thứ tự của các cặp key-value. Nó cho phép mộtkeylànullvà nhiềuvaluelànull. - Hiệu năng: Giống như
HashSet, nó cho hiệu năng trung bình O(1) cho các thao tácputvàget. Đây là lựa chọn mặc định khi bạn cần mộtMap.
LinkedHashMap
- Đặc điểm: Kế thừa từ
HashMap,LinkedHashMapbổ sung khả năng duy trì thứ tự chèn (insertion-order) của các cặp key-value, tương tự nhưLinkedHashSet. - Khi nào nên dùng? Rất hữu ích khi bạn cần duyệt qua các entry trong
Maptheo đúng thứ tự chúng đã được thêm vào, ví dụ như xây dựng một bộ nhớ đệm (cache) LRU.
TreeMap SortedMap sortedMap = new TreeMap<>();
// Sắp xếp các cặp key-value dựa trên key.
Map<String, Integer> treeMap = new TreeMap<>();
treeMap.put("C", 3);
treeMap.put("A", 1);
treeMap.put("B", 2);
// Khi duyệt qua, output sẽ là A, B, C
System.out.println(treeMap); // {A=1, B=2, C=3}- Lưu trữ:
TreeMaplưu trữ các entry trong một cây đỏ-đen, tương tự nhưTreeSet. - Đặc điểm: Nó sắp xếp các cặp key-value dựa trên key. Các key phải có khả năng so sánh được (triển khai
Comparable) hoặc bạn phải cung cấp mộtComparator. - Khi nào nên dùng? Khi bạn có nhu cầu lấy ra các entry từ
Maptheo một thứ tự đã được sắp xếp của các key.
Lớp tiện ích Collections của Java collection framework
Ngoài các interface và lớp triển khai, Java Collection Framework còn cung cấp một bộ công cụ mạnh mẽ là lớp tiện ích Collections. Đồng thời, việc hiểu các cách duyệt qua phần tử sẽ giúp bạn xử lý dữ liệu một cách linh hoạt và hiệu quả.
Lớp tiện ích Collections
Đừng nhầm lẫn với interface Collection (không có ‘s’), lớp tiện ích Collections (có ‘s’ ở cuối) là một lớp chứa đầy các phương thức static hữu ích để thực hiện các thao tác phổ biến trên collection, đặc biệt là List.
Dưới đây là một số phương thức quan trọng mà bạn sẽ thường xuyên sử dụng:
- sort(List<T> list): Sắp xếp các phần tử trong một
Listtheo thứ tự tự nhiên của chúng. Đây là một trong những phương thức được sử dụng nhiều nhất.
List<Integer> numbers = new ArrayList<>(Arrays.asList(5, 2, 8, 1));
Collections.sort(numbers);
// numbers bây giờ là [1, 2, 5, 8]- shuffle(List<?> list): Xáo trộn ngẫu nhiên vị trí của các phần tử trong
List. Rất hữu ích khi bạn cần tạo ra sự ngẫu nhiên, ví dụ như trong một trò chơi rút bài. - reverse(List<?> list): Đảo ngược thứ tự các phần tử trong
List. Phần tử cuối cùng sẽ trở thành đầu tiên và ngược lại. - binarySearch(List<?> list, T key): Tìm kiếm một phần tử trên một
Listđã được sắp xếp bằng thuật toán tìm kiếm nhị phân. Phương thức này cho hiệu năng rất cao (O(log n)). - max(Collection<?> coll) và min(Collection<?> coll): Dễ dàng tìm thấy phần tử lớn nhất hoặc nhỏ nhất trong một collection.
Các cách duyệt qua một Collection
Việc lặp qua các phần tử là một thao tác cơ bản và có nhiều cách để thực hiện, mỗi cách có ưu điểm riêng.
1. Vòng lặp for-each (Enhanced for-loop)
Đây là cách tiếp cận đơn giản, dễ đọc và phổ biến nhất. Cú pháp của nó rất gọn gàng và che giấu đi sự phức tạp của việc duyệt.
List<String> fruits = Arrays.asList("Apple", "Banana", "Cherry");
for (String fruit : fruits) {
System.out.println(fruit);
}Khi nào nên dùng? Hầu hết các trường hợp khi bạn chỉ cần duyệt qua các phần tử mà không cần xóa chúng.
2. Sử dụng Iterator
Iterator là một interface cung cấp một cách chuẩn hóa để duyệt qua collection. Nó đặc biệt quan trọng vì cho phép xóa phần tử một cách an toàn ngay trong khi duyệt.
Iterator cung cấp ba phương thức chính:
hasNext(): Trả về true nếu còn phần tử tiếp theo.next(): Trả về phần tử tiếp theo.remove(): Xóa phần tử hiện tại mànext()vừa trả về.
List<Integer> numbers = new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5));
Iterator<Integer> iterator = numbers.iterator();
while (iterator.hasNext()) {
Integer number = iterator.next();
if (number % 2 == 0) { // Xóa các số chẵn
iterator.remove(); // An toàn để xóa!
}
}
// numbers bây giờ là [1, 3, 5]Lưu ý: Cố gắng xóa phần tử bằng phương thức remove() của collection (numbers.remove(number)) bên trong vòng lặp for-each sẽ gây ra lỗi ConcurrentModificationException.
3. Java 8 Stream API
Kể từ Java 8, Stream API đã mang đến một cách tiếp cận hoàn toàn mới, mạnh mẽ và linh hoạt để xử lý collection. Nó cho phép bạn thực hiện các thao tác phức tạp trên dữ liệu theo một luồng (pipeline) một cách khai báo (declarative).
Thay vì viết code nói “làm thế nào” để duyệt và xử lý (như vòng lặp for), bạn chỉ cần nói “muốn gì”.
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "Anna");
// Lọc ra các tên bắt đầu bằng "A", chuyển thành chữ hoa và in ra
names.stream()
.filter(name -> name.startsWith("A")) // Lọc
.map(String::toUpperCase) // Biến đổi
.forEach(System.out::println); // Hành động cuối cùng
// Output:
// ALICE
// ANNAStream API cung cấp vô số các thao tác như filter, map, reduce, collect… giúp viết mã ngắn gọn, dễ đọc và dễ song song hóa hơn.
Lời khuyên để sử dụng Java collection framework hiệu quả
Việc sử dụng thành thạo Java Collection Framework không chỉ dừng lại ở việc biết có những collection nào. Để viết mã nguồn chuyên nghiệp, dễ bảo trì và hiệu quả, bạn nên tuân thủ các nguyên tắc và thực hành tốt nhất dưới đây.
Lập trình hướng về Interface
Đây là một trong những nguyên tắc quan trọng nhất trong lập trình hướng đối tượng và đặc biệt hữu ích với Collection Framework.
Nguyên tắc: Luôn khai báo biến bằng kiểu Interface thay vì kiểu Class cụ thể.
Thay vì viết: ArrayList<String> names = new ArrayList<>();
Hãy viết: List<String> names = new ArrayList<>();
Cách làm này giúp mã nguồn của bạn trở nên linh hoạt hơn. Nếu trong tương lai, bạn nhận ra LinkedList phù hợp hơn cho bài toán của mình vì cần thêm/xóa nhiều, bạn chỉ cần thay đổi một chỗ duy nhất:
List<String> names = new LinkedList<>();
Toàn bộ phần code còn lại sử dụng biến names sẽ không cần phải thay đổi, vì chúng đều đang hoạt động dựa trên các phương thức được định nghĩa trong List interface.
Luôn sử dụng Generics (<>)
Generics là một tính năng cực kỳ mạnh mẽ được giới thiệu từ Java 5 để đảm bảo an toàn kiểu dữ liệu (type safety).
Lợi ích:
- Phát hiện lỗi ở thời điểm biên dịch (compile-time): Generics ngăn bạn thêm sai kiểu dữ liệu vào một collection ngay khi viết mã, thay vì để chương trình chạy rồi phát sinh lỗi
ClassCastException. - Không cần ép kiểu thủ công: Bạn không cần phải ép kiểu một cách tường minh khi lấy phần tử ra khỏi collection, giúp mã nguồn sạch sẽ và an toàn hơn.
// Không dùng Generics (không nên)
List names = new ArrayList();
names.add("Alice");
names.add(123); // Lỗi logic nhưng chương trình vẫn biên dịch
String name = (String) names.get(1); // Lỗi ClassCastException khi chạy
// Có dùng Generics (nên dùng)
List<String> safeNames = new ArrayList<>();
safeNames.add("Alice");
// safeNames.add(123); // Lỗi ngay tại lúc biên dịch!
String safeName = safeNames.get(0); // Không cần ép kiểuChọn Đúng Collection Cho Đúng Công Việc
Việc lựa chọn sai cấu trúc dữ liệu có thể khiến hiệu năng của ứng dụng giảm sút nghiêm trọng. Hãy luôn tự hỏi: “Mình cần làm gì với dữ liệu này?”
- Cần truy cập ngẫu nhiên qua index thường xuyên? Dùng
ArrayList. - Cần thêm/xóa phần tử ở đầu/cuối/giữa danh sách liên tục? Dùng
LinkedList. - Cần đảm bảo các phần tử là duy nhất và không quan tâm thứ tự? Dùng
HashSetđể có hiệu năng cao nhất. - Cần lưu trữ các cặp key-value để tra cứu nhanh? Dùng
HashMap. - Cần dữ liệu luôn được sắp xếp? Dùng
TreeSethoặcTreeMap.
Hiểu rõ về equals() và hashCode()
Đây là một điểm cực kỳ quan trọng nhưng thường bị bỏ qua, đặc biệt khi bạn làm việc với các collection dựa trên cơ chế băm như HashSet và HashMap.
Các collection này sử dụng hashCode() để xác định “xô” (bucket) nơi một đối tượng sẽ được lưu trữ để tìm kiếm nhanh. Sau đó, chúng dùng equals() để so sánh và xác nhận đối tượng đó có thực sự tồn tại trong “xô” hay không.
Quy tắc vàng (The Contract):
- Nếu hai đối tượng bằng nhau theo phương thức
equals(), chúng bắt buộc phải có cùng một giá trịhashCode(). - Nếu hai đối tượng có cùng
hashCode(), chúng không nhất thiết phải bằng nhau theoequals().
Nếu bạn override equals() mà không override hashCode() cho các đối tượng của mình, HashSet và HashMap sẽ hoạt động sai, dẫn đến việc không tìm thấy đối tượng dù nó đã có trong collection hoặc lưu trữ các đối tượng trùng lặp.
Các câu hỏi thường gặp
ArrayList và Vector khác nhau ở điểm nào?
Điểm khác biệt chính nằm ở tính đồng bộ (synchronization):
Vector: Là một lớp cũ (legacy class), tất cả các phương thức của nó đều được synchronized. Điều này có nghĩa làVectoran toàn cho luồng (thread-safe), nhiều luồng có thể truy cập vào nó mà không gây ra lỗi dữ liệu. Tuy nhiên, chính vì cơ chế này mà hiệu năng của nó sẽ chậm hơn.ArrayList: Không được đồng bộ hóa, vì vậy nó không an toàn cho luồng. Đổi lại,ArrayListcó hiệu năng cao hơn trong môi trường đơn luồng.
Lời khuyên: Trong hầu hết các trường hợp, hãy ưu tiên sử dụng ArrayList. Nếu bạn cần một danh sách an toàn cho luồng, hãy sử dụng Collections.synchronizedList(new ArrayList<>()) hoặc các collection trong package java.util.concurrent như CopyOnWriteArrayList.
HashMap và Hashtable khác nhau như thế nào?
Giống như cặp ArrayList/Vector, sự khác biệt chính cũng nằm ở tính đồng bộ và một vài điểm khác:
Hashtable: Là một lớp cũ, được đồng bộ hóa (thread-safe) và hiệu năng chậm hơn. Quan trọng là,Hashtablekhông cho phép bất kỳkeyhayvaluenào lànull.HashMap: Không được đồng bộ hóa và có hiệu năng cao hơn.HashMapcho phép một key lànullvà nhiềuvaluelànull.
Lời khuyên: Hãy luôn ưu tiên HashMap. Nếu cần một Map an toàn cho luồng, hãy sử dụng Collections.synchronizedMap(new HashMap<>()) hoặc ConcurrentHashMap.
Tại sao Map không kế thừa (extends) Collection?
Đây là một câu hỏi về mặt thiết kế của framework. Mặc dù Map cũng là một cấu trúc dữ liệu để chứa các đối tượng, nhưng triết lý của nó khác biệt cơ bản so với Collection:
- Collection: Đại diện cho một tập hợp các phần tử đơn lẻ. Các hành vi cốt lõi của nó xoay quanh việc thêm, xóa, chứa một phần tử (
add(element),contains(element)). - Map: Đại diện cho một tập hợp các cặp key-value. Các hành vi cốt lõi của nó xoay quanh
keynhưput(key, value),get(key),containsKey(key).
Cấu trúc và mục đích sử dụng của chúng quá khác nhau để có thể hợp nhất vào chung một hệ thống kế thừa. Map không phải là một “Collection của các phần tử”, mà là một cấu trúc ánh xạ riêng biệt.
Khi nào thì nên dùng Iterator thay cho vòng lặp for-each?
Hãy dùng Iterator khi bạn có nhu cầu xóa phần tử khỏi collection ngay trong lúc đang duyệt qua nó.
Vòng lặp for-each rất tiện lợi và dễ đọc, nhưng nếu bạn cố gắng gọi phương thức collection.remove() bên trong nó, chương trình sẽ ném ra một ngoại lệ ConcurrentModificationException. Iterator cung cấp phương thức iterator.remove() được thiết kế riêng để xử lý việc này một cách an toàn.
// Dùng Iterator để xóa phần tử một cách an toàn
Iterator<String> iterator = myList.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
if (someCondition) {
iterator.remove(); // Đúng và an toàn!
}
}Kết luận
Java Collection Framework là một phần không thể thiếu và vô cùng mạnh mẽ của ngôn ngữ Java. Bằng việc nắm vững cấu trúc từ các Interface cốt lõi, hiểu rõ đặc điểm của từng lớp triển khai cụ thể, và áp dụng các thực hành tốt nhất, bạn có thể viết mã nguồn không chỉ chạy đúng mà còn hiệu quả, rõ ràng và dễ bảo trì.
Hy vọng qua bài viết này, bạn đã có một cái nhìn tổng quan và vững chắc về framework quan trọng này. Chìa khóa để thực sự thành thạo chính là thực hành – hãy thử nghiệm với các loại collection khác nhau trong những dự án của riêng bạn để cảm nhận sự khác biệt.
